Das Thema Grammatiken soll zunächst im Skript nicht behandelt werden, damit ein gutes Kapitel zu den schwierigen Turing-Maschinen und der Komplexitätstheorie entstehen kann. Für die nicht ganz so komplizierten Grammatiken sei auf die Folien und bei Bedarf auf das Buch von Hopcroft, Ullman und Motwani verwiesen.
Eine kurze Übersicht über den behandelten Stoff wollen wir an dieser Stelle aber geben. Wenn einem das alles etwas sagt und man damit arbeiten kann, dann kennt man sich in diesem Teil gut aus.
Wir haben zunächst die Grammatik eingeführt. Dort waren dann noch die Begriffe Nonterminal, Terminal, Produktion und Startsymbol wichtig. Diese beschreiben quasi was eine Grammatik ist. Um auch zu beschreiben, was man mit einer Grammatik machen kann, waren dann die Begriffe Ableitung und (Generierte) Sprache wichtig und nebenher noch der Begriff der Äquivalenz.
Dann haben wir die Grammatiken eingeschränkt und haben die kontextfreie Grammatik (oder auch Typ-2-Grammatik) und die rechtslineare Grammatik (auch Typ-3-Grammatik) eingeführt. Bei kontextfreien Grammatiken traten dann noch die Begriffe \(\lambda\)-Produktion und \(\lambda\)-frei auf.
Für die kontextfreien Grammatiken haben wir die Sprachfamilie CF (context free) eingeführt.
Wir haben dann zwei Konstruktionstechniken für Grammatiken kennengelernt, Abschlusseigenschaften der Sprachfamilie CF betrachtet und gesehen, dass rechtslineare Grammatiken und DFAs äquivalent sind sowie erwähnt, dass kontextfreie Grammatiken und Kellerautomaten äquivalent sind.
Dann haben wir die Chomsky-Normalform kennengelernt und ein Verfahren betrachtet, wie man diese herstellen kann. Im ersten Schritt dieses Verfahrens war zudem ein Test enthalten, mit dem man testen kann, ob \(\lambda \in L(G)\) gilt und im dritten Schritt war ein Verfahren enthalten, mit dem man eine Grammatik reduzieren kann.
Zum Schluss haben wir dann noch das Pumping Lemma für kontextfreie Sprachen kennengelernt und damit gezeigt, dass es Sprachen gibt, die nicht kontextfrei sind.
Mittlerweile haben wir mit DFAs, NFAs, \(\lambda\)-NFAs und regulären Ausdrücken vier verschiedene Formalismen kennen gelernt, die die Familie der regulären Sprachen erfassen, d.h. jede von einem dieser drei Automatenmodelle akzeptierte und jede von einem regulären Ausdruck beschriebene Sprache, ist eine reguläre Sprache. Wir haben dann noch die Abschlusseigenschaften kennengelernt und gesehen, dass es auch gar nicht so leicht ist, keine reguläre Sprache mehr zu haben. Vereinigt man z.B. zwei reguläre Sprachen, so hat man wieder eine, ebenso beim Durchschnitt und auch das Komplement einer regulären Sprache ist stets regulär.
Es erscheint aber unwahrscheinlich, dass alle Sprachen regulär sind. Der DFA kann ja nur endlich viele Informationen speichern und sich auch keine Informationen mehrmals ansehen. Intuitiv kann man also gut vermuten, dass es doch Sprachen geben sollte, die nicht regulär sind. Aber wie könnte eine solche Sprache aussehen? Und wie beweist man, dass eine Sprache tatsächlich nicht regulär ist?
Pause to Ponder: Für welche Sprache könnte es unmöglich sein, einen endlichen Automaten zu konstruieren, der sie akzeptiert?
Da ein endlicher Automat nur endlich viele Informationen speichern kann, sollten wir dann an die Grenzen endlicher Automaten stossen, wenn wir uns unendlich viele Informationen merken müssen bzw. zwar endlich viele, aber von der Länge des Eingabewortes abhängig viele Informationen. Müssten wir uns z.B. bei einem Eingabewort der Länge \(10\) gerade \(10\) Informationen merken, bräuchten wir \(10\) Zustände. Ist das dann aber auch für ein Eingabewort der Länge \(100\) und \(1000\) nötig, dann gibt es keine obere Grenze für die Zustände und es kann keinen endlichen Automaten für die Sprache geben.
Ein guter Kandidat ist daher vielleicht die Sprache \(L = \{a^n b^n \mid n \in \mathbb{N}\}\). Diese Sprache ist nicht zu kompliziert zu beschreiben und dennoch erfüllt sie intuitiv obiges. Wenn wir nämlich die \(n\) \(b\)s lesen wollen, so müssen wir uns vorher die Zahl \(n\) merken, also die Anzahl der gelesenen \(a\)s und diese Zahl ist wie oben gewünscht abhängig von der Wortlänge. Wir müssten einen Zustande haben, in dem wir uns merken, dass wir ein \(a\) gelesen haben, einen, in dem wir uns merken, dass es zwei waren usw. Da die Zahl beliebig groß werden kann, kann es intuitiv keinen DFA geben, der sich alle diese Zahlen in seinen nur endlich vielen Zuständen merkt.
Dies ist aber zunächst nur eine Intuition. Wie beweisen wir nun, dass obiges \(L\) tatsächlich nicht regulär ist? Hier hilft uns das sogenannte Pumping Lemma.
Das Pumping Lemma
Das Pumping Lemma macht eine Aussage über alle regulären Sprachen, d.h. es beschreibt eine Eigenschaft, die alle regulären Sprachen haben. Hat eine Sprache diese Eigenschaft also nicht, so kann sie nicht regulär sein. Um uns dem Pumping Lemma zu nähern, machen wir uns einmal selbst auf die Suche nach einer Eigenschaft \(X\), die jede reguläre Sprache haben muss. Wir wissen bisher von regulären Sprachen, das es zu jeder reglären Sprache einen DFA gibt, der sie akzeptiert. Von DFAs wiederum wissen wir, dass sie nur endlich viele Zustände haben. Dies können wir versuchen auszunutzen.
Pause to Ponder: Wie können wir dies ausnutzen, um eine Eigenschaft zu erhalten, die jede reguläre Sprache haben muss? Tipp: Man lege dem Automaten ein Wort vor, dass länger ist als die Anzahl der Zustände. Was passiert?
Legt man einem Automaten mit \(n\) Zuständen ein Wort vor, dass z.B. die Länge \(4 \cdot n\) hat, dann muss der Automat, wenn er das Wort akzeptiert, mindestens einen Zustand mehrfach besuchen. Bei jedem gelesene Symbol findet ja ein Zustandswechsel statt und wenn man \(4 \cdot n\) Symbole liest, finden also \(4 \cdot n\) Zustandswechsel statt. Hat man nur \(n\) Zustände zur Auswahl muss zwangsläufig mindestens einer mehrfach auftreten. Das heißt auch, dass beim Lesen des Wortes der Automat Schleifen durchwandert. Diese Schleifen könnte man mehrfach entlang gehen und so neue Worte erzeugen, die alle auch in der Sprache sein müssten. Damit haben wir eine schöne Eigenschaft regulärer Sprachen gefunden. Für alle Worte der Sprache ab einer bestimmten Länge muss gelten, dass man sie so zerlegen kann, dass ein Teilstück des Wortes beliebig oft wiederholt werden kann und das Wort dennoch weiterhin in der Sprache ist.
Pause to Ponder: Wie hilft uns das bei der eingangs erwähnten Sprache \(L = \{a^n b^n \mid n \in \mathbb{N}\}\)?
Hätte man für \(L\) einen Automaten mit \(k\) Zuständen, dann betrachtet man \(a^k b^k\). Nach obigem müsste schon beim Lesen der ersten \(k\) Symbole (also der \(a\)s) ein Zustand mehrfach auftreten, d.h. wir haben dann bereits beim Lesen der \(a\)s eine Schleife und könnten diese Schleife auch mehrfach entlang gehen. Nach obigem Überlegungen müssten die dabei entstehenden Wort ja alle in der Sprache \(L\) sein (da sie ja weiterhin von unserem angenommenen Automaten akzeptiert werden müssten). Dies klappt aber nicht, da wir ja Worte der Art \(a^{k+j} b^k\) erzeugen würden, die gerade nicht in \(L\) sind.
Die oben erarbeitete Vorstellung der speziellen Eigenschaft aller regulären Sprachen wird nachfolgend im Pumping Lemma formalisiert und bewiesen. Im Beweis finden sich etliche der oben schon angedeuteten Argumente wieder. Im Anschluss an den Beweis nutzen wir das Pumping Lemma dann, um für \(L = \{a^n b^n \mid n \in \mathbb{N}\}\) eindeutig nachzuweisen, dass diese Sprache nicht regulär ist. Auch in dem Beweis finden sich dann die Überlegungen von eben als überzeugende Argumente wieder.
Lemma 2.4.1 (Pumping Lemma)
Sei \(L \in \text{REG}\) eine reguläre Sprache. Dann gibt es ein \(n \geq 1\), so dass jedes Wort \(z \in L\) mit \(|z| \geq n\) in die Form \(z = uvw\) zerlegt werden kann, wobei
\(|uv| \leq n\)
\(|v| \geq 1\)
\(uv^iw \in L\) für jedes \(i \in \mathbb{N}\) (inkl. der \(0\))
(Äquivalent zur letzten Aussage ist die Aussage \(\{u\}\{v\}^*\{w\} \subseteq L\).)
Bevor wir zum Beweis kommen, betrachten wir das Lemma noch einmal genauer. Wie oben in den Überlegungen schon beschrieben, macht es eine Aussage über reguläre Sprachen. Wenn eine Sprache also regulär ist, dann gilt das Pumping Lemma. Es sagt dann, dass es eine natürliche Zahl \(n \geq 1\) gibt derart, dass jedes Wort \(z\) aus \(L\), das mindestens die Länge \(n\) hat, zerlegt werden kann in \(z = uvw\).
Wie ein Wort \(z\) in Teilworte \(uvw\) zerlegt wird, bereitet bisweilen Probleme. Mit \(z = uvw\) wird ausgesagt, dass \(z\) in drei Teilworte, nämlich \(u\), \(v\) und \(w\), zerlegt wird, wobei \(u\), \(v\) und \(w\) hintereinander geschrieben gerade wieder \(z\) ergeben. Hat man z.B. das Wort \(z = \text{Hausboot}\), dann ist z.B. \(u = \text{Hau}\), \(v = \text{sb}\) und \(w = \text{oot}\) eine Zerlegung von \(z\) in \(u\), \(v\) und \(w\) mit \(z = uvw\). Man beachte, dass der erste Buchstabe von \(u\) der erste Buchstabe von \(z\) ist und der letzte Buchstabe von \(w\) der letzte Buchstabe von \(z\). Betrachtet man dann z.B. \(uv^2w\) (was wir bei der dritten Eigenschaft des Pumping Lemmas brauchen), dann ist dies gerade \(uvvw\) also mit der obigen Bedeutung von \(u\), \(v\) und \(w\) dann also \(Hau \cdot sb \cdot sb \cdot oot = Hausbsboot\). Man beachte, dass bei einer Zerlegung \(z = uvw\) oft auch z.B. \(u = \lambda\) möglich ist. In diesem Fall ist der erste Buchstabe von \(v\) dann der erste Buchstabe von \(z\).
Die Zerlegung \(z = uvw\) aus dem Pumping Lemma erfüllt dann drei Eigenschaften, von denen wir die dritte oben bereits skizziert haben: Man kann einen Teil des Wortes (hier das \(v\)) beliebig oft schreiben und erhält stets ein Wort aus \(L\). Das Wort \(v\) entspricht im Automaten aus den vorherigen Überlegungen der Schleife. Dies wird auch gleich im Beweis deutlich werden. Die erste und zweite Eigenschaft besagen, dass die Schleife existieren muss, also mindestens die Länge \(1\) haben muss (zweite Eigenschaft) und dass diese bis zu einem bestimmten Zeitpunkt das erste Mal entlang gegangen sein muss (erste Eigenschaft). Die erste Eigenschaft rührt daher, dass bei einem Automaten mit \(n\) Zuständen nach \(n\) gelesenen Symbolen bereits \(n+1\) Zustände besucht wurden (der Startzustand und nach jedem gelesenen Symbol ein weiterer). Hat man nur \(n\) Zustände ist spätestens der \(n+1\)-te Zustand also ein Zustand, den man schon einmal besucht hatte.
Man beachte noch, dass die dritte Eigenschaft besagt, dass mit \(z = uvw \in L\) für jedes \(i \geq 0\) auch \(uv^iw \in L\) gilt. Insbesondere kann \(i\) auch \(0\) sein und in diesem Fall haben wir \(uv^0w = uw\). Es müssen also \(uw\) ebenso wie \(uvvw\), \(uvvvw\) usw. alle in \(L\) sein.
Wir beweisen nun das Pumping Lemma. Man achte beim Durcharbeiten darauf, wo sich die obigen Ideen überall wiederfinden.
Beweis
Sei \(L\) regulär. Dann gibt es einen DFA, der \(L\) akzeptiert und sogar einen vollständigen DFA, der \(L\) akzeptiert. Sei dieser vollständige DFA mit \(A\) benannt. Es gilt also \(L(A) = L\) und \(A\) ist zudem vollständig. \(A\) hat eine Menge von Zuständen. Sei \(n\) die Anzahl dieser Zustände von \(A\). Wir müssen nun zeigen, dass jedes Wort \(z\) aus \(L\), dessen Länge mindestens \(n\) ist, in \(z = uvw\) zerlegt werden kann, wobei \(u\), \(v\) und \(w\) die drei Eigenschaften des Lemmas erfüllen.
Sei also \(z \in L\) mit \(|z| \geq n\) (gibt es kein solches \(z\) ist nichts zu zeigen, da das Pumping Lemma ja nur für Worte mit dieser Eigenschaft etwas fordert; gibt es also keine solchen Worte, gilt das Pumping Lemma sofort). Wir legen nun \(A\) das Wort \(z\) vor. \(A\) beginnt dann eine Rechnung in seinem Startzustand \(z_s\). Da \(A\) vollständig ist kann \(z\) bis zum Ende gelesen werden. (Ferner endet \(A\) dann in einem Endzustand, da \(z \in L\) ist. Dies benötigen wir aber jetzt noch nicht.) Da \(z\) aus mindestens \(n\) Buchstaben besteht, finden mindestens \(n\) Zustandsübergänge statt, d.h. es werden inklusive des Startzustandes mindestens \(n+1\) Zustände besucht. Da es aber nur \(n\) Zustände gibt, muss mindestens ein Zustand doppelt auftreten.
Sei die Zustandsfolge, die in \(A\) vom Startzustand \(z_s\) zu einem Endzustand \(z_e\) beim Lesen von \(z\) besucht wird durch \(z_0, z_1, z_2, \ldots, z_n, \ldots, z_q\) gegeben. Hier ist also \(z_0 = z_s\) und \(z_q = z_e\) und die Indizes geben an, der wievielte Zustand gerade besucht wird. Man beachte, dass die Indizierung hier nichts mit den verschiedenen Zuständen aus \(Z\) zu tun hat. Es könnte also z.B. \(z_1 = z_2\) sein. Wir wissen nun nach obigem, dass ein Zustand mehrfach auftreten muss. Seien daher \(z_i\) und \(z_j\) mit \(i \not= j\) und \(i < j\) in dieser Folge gleich und außerdem \(z_j\) der erste Zustand, der ein zweites Mal auftritt. Da von \(z_0\) bis \(z_n\) bereits \(n+1\) Zustände in der Zustandsfolge auftreten, es aber nur \(n\) Zustände gibt, muss hier bereits ein Zustand doppelt auftreten, d.h. es muss \(j \leq n\) gelten. Ferner muss wegen \(i \not= j\) und \(i < j\) (\(z_i\) und \(z_j\) treten in der Folge nicht zum gleichen Zeitpunkt auf und \(z_j\) ist gerade die erste Wiederholung von \(z_i\)) \(j – i \geq 1\) gelten.
Wir können nun das Wort \(z\), das uns ja von \(z_0\) nach \(z_q\) in der obigen Zustandsfolge bringt, an \(i\) und \(j\) zerlegen. Sei dazu
\(u\) das Wort, das von \(z_0\) bis \(z_i\) gelesen wird,
\(v\) das Wort, das von \(z_i\) bis \(z_j\) gelesen wird und
\(w\) das Wort, das von \(z_j\) bis \(z_q\) gelesen wird.
Damit ist \(uvw = z\). Nach obigen Ausführungen zur Wahl von \(i\) und \(j\) ist ferner \(|uv| \leq n\) (wegen \(j \leq n\) oben) und \(|v| \geq 1\) (wegen \(j-i \geq 1\) oben). Die gewählte Zerlegung von \(z\) in \(uvw\) erfüllt also schon die ersten beiden Bedingungen im Pumping Lemma.
Da \(z_i = z_j\) gilt, aber \(i \not= j\) ist, überführt das Wort \(v\) den Automaten also von \(z_i\) zurück nach \(z_i (= z_j)\). Diese Schleife (bzw. besser: dieser Kreis) im Automaten kann beliebig oft entlang gegangen werden und egal wie oft man diese Schleife entlang geht, also egal wie oft man das Teilwort \(v\) liest, man ist im Anschluss in \(v_j\) und kann von hieraus mit \(w\) in einen Endzustand gelangen (erst an dieser Stelle wird benötigt, dass \(v_q\) ein Endzustand ist, da ursprünglich ja auch \(v\) von \(A\) akzeptiert wurde). Daraus folgt aber nun, dass \(u v^i w\) für alle \(i \geq 0\) akzeptiert wird und also auch die dritte Bedingung im Pumping Lemma von unserer gewählten Zerlegung erfüllt wird. Damit haben wir das Pumping Lemma bewiesen.
Wir wollen nun das Pumping Lemma nutzen, um zu zeigen, dass die Sprache \(\{a^n b^n \mid n \in \mathbb{N}\}\) nicht regulär ist. Dazu nehmen wir an, die Sprache wäre regulär und zeigen einen Widerspruch. Wir führen den Beweis zunächst sehr ausführlich und bauen etliche Erklärungen in den Beweis ein. Wir betonen aber schon hier, dass wir bei einem Widerspruchsbeweis annehmen, dass das Pumping Lemma gilt und dann einen Widerspruch herstellen wollen. Da das Pumping Lemma sagt, dass alle Worte mit \(z \in L\) und \(|z| \geq n\) zerlegt werden können, genügt es für ein Wort mit \(z \in L\) und \(|z| \geq n\) zu zeigen, dass dem nicht so ist. Da das Pumping Lemma dann sagt, dass eine Zerlegung \(z = uvw\) existiert, die die drei Eigenschaften erfüllt (also erstens \emph{und} zweitens und drittens), muss man dann zeigen, dass jede Zerlegungen von \(z\) in \(uvw\) mindestens eine der drei Eigenschaften nicht erfüllt (also alle Zerlegungen im Widerspruch zu erstens, zweitens oder drittens stehen).
Satz 2.4.2
\(L := \{a^n b^n \mid n \in \mathbb{N}\}\) ist nicht regulär.
Beweis
Angenommen \(L\) wäre regulär. Dann gilt das Pumping Lemma. Sei \(k\) die Zahl aus dem Pumping Lemma.
An dieser Stelle bereits der erste Hinweis: Die Zahl \(k\) wird nicht genauer spezifiziert. Es geht lediglich darum, dass es \(k\) geben müsste, wenn denn das Pumping Lemma gilt. Es macht auch wenig Sinn, diese Zahl hier genauer spezifizieren zu wollen. Sie hing im Beweis des Pumping Lemmas ja mit der Anzahl der Zustände eines Automaten zusammen, der \(L\) akzeptiert. Wenn unser Widerspruchsbeweis nachfolgend also erfolgreich ist und wir tatsächlich zeigen, das \(L\) nicht regulär ist, dann gibt es ja gerade keinen DFA für \(L\) und dann macht es auch keinen Sinn zu versuchen, dessen Anzahl an Zuständen zu ermitteln.
Wir betrachten nun das Wort \(z = a^k b^k\). Es gilt \(z \in L\) und \(|z| \geq k\).
Bei der Wahl von \(z\) sind wir recht frei und es ist tatsächlich bei manchen Sprachen viel Kreativität nötig, um auf ein gutes \(z\) zu kommen (d.h. eines mit dem man arbeiten kann und das einem nachher tatsächlich erlaubt, zu einem Widerspruch zu kommen). Das \(z\) muss aber in \(L\) sein und es muss von der Zahl \(k\) abhängen (also von jener Zahl, dessen Existenz aus der angenommenen Gültigkeit des Pumping Lemmas folgt). Warum muss \(z\) von \(k\) abhängen? Weil wir ein Wort benötigen, dass in \(L\) ist und \(|z| \geq k\) erfüllt und um sicherzustellen, dass die Länge von \(z\) mindestens \(k\) ist, muss das \(k\) irgendwie in \(z\) auftreten.
Nun muss es nach dem Pumping Lemma eine Zerlegung \(z = uvw\) geben, die die drei Eigenschaften erfüllt. Wir wollen dies zum Widerspruch führen. Wir betrachten dazu nun nur jene Zerlegungen, die die erste und zweite Bedingung erfüllen und zeigen, dass diese im Widerspruch zur dritten stehen. Wir haben dann gezeigt, dass jede Zerlegung von \(z\) in \(uvw\) im Widerspruch zu einer der drei Bedingungen steht und sind dann fertig.
Warum müssen hier alle Zerlegungen betrachtet werden? Im Pumping Lemma ist ja nur von einer die Rede? Letzteres ist zwar richtig, wir wollen ja aber gerade einen Widerspruch erzeugen. Um also zu zeigen, dass es nicht stimmt, dass es eine Zerlegung von \(z\) in \(uvw\) gibt, die die drei Eigenschaften erfüllt, müssen wir zeigen, dass es keine solche Zerlegung gibt. Dazu müssen wir zeigen, dass alle Zerlegungen einen Widerspruch erzeugen, dass also jede Zerlegung von \(z\) in \(uvw\) mit mindestens einer der drei Eigenschaften im Widerspruch steht.
Und warum genügt es dann nur jene zu betrachten, die die ersten beiden Eigenschaften erfüllen? Das ist ganz einfach: Eine Zerlegung, die nicht die ersten beiden Eigenschaften erfüllt, erfüllt ja bereits mindestens eine der drei Eigenschaften nicht (nämlich eine der ersten beiden). Es genügt also sich die Zerlegungen anzugucken, die die beiden ersten Eigenschaften erfüllen und dann herzuleiten, dass diese Zerlegungen nun aber im Widerspruch zur dritten Eigenschaft stehen. Damit hat man dann gezeigt, dass alle Zerlegungen zu den drei Eigenschaften im Widerspruch stehen. Entweder widerspricht eine Zerlegung dann schon einer der ersten beiden Eigenschaften oder, wenn sie die ersten beiden Eigenschaften erfüllt, dann widerspricht sie der dritten.
Der Grund für dieses Vorgehen ist, dass man über Zerlegungen, die die ersten beiden Eigenschaften erfüllen schon etwas weiß (nämlich die Aussagen der ersten beiden Eigenschaften) und dass man dann damit arbeiten kann.
Sei also \(z = a^k b^k = uvw\) eine Zerlegung mit \(i) |uv| \leq k\) und \(ii) |v| \geq 1\). Da \(uv\) ja in den ersten Buchstaben von \(z\) liegt (wgen \(z = uvw\)) und da \(uv\) aber höchstens die Länge \(k\) hat, muss \(uv\) also in den ersten \(k\) Buchstaben von \(z\) liegen (beginnend bei dem ersten), d.h. in den ersten \(k\) \(a\)s. Beachtet man ferner, dass \(|v| \geq 1\) gilt, so kann man bereits \(v \in \{a\}^+\) schlussfolgern. Genauer kann man sogar sagen, dass es ein \(j\) mit \(1 \leq j \leq k\) geben muss derart, dass \(v = a^j\) gilt.
Man beachte, dass wir an dieser Stelle jede Zerlegung \(z = uvw\), die \(i)\) und \(ii)\) erfüllt, betrachten. Durch \(j\) und dadurch, dass wir nicht genauer spezifizieren, wo \(v\) beginnt (bzw. wo \(u\) endet), haben wir diese Zerlegungen quasi parametrisiert. Eine Zerlegung ist z.B. \(u = \lambda\), \(v = a\), \(w = a^{k-1}b^k\), eine weitere ist \(u = a\), \(v = a\), \(w = a^{k-2}b^k\), noch eine ist \(u = aa\), \(v = a\), \(w = a^{k-3}b^k\). Es gibt dann weitere wie z.B. \(u = aa\), \(v = aaa\), \(w = a^{k-5}b^k\) usw. Allen diese Zerlegungen ist gemein, dass \(u\) in den \(a\)s liegt (ganz genau: \(u\) ist zwischen \(a^0 = \lambda\) und \(a^{k-1}\)), dass dann \(v\) folgt und \(v\) nur aus \(a\)s besteht, mindestens aus einem und maximal aus \(k\) vielen, wobei einige Fälle je nach Wahl von \(u\) nicht eintreten können und dass \(w\) dann den Rest von \(z\) ausmacht.
Wir betrachten nun das Wort \(u v^2 w = uvvw\), dass nach der dritten Bedingung in \(L\) sein müsste. Es ist aber \(u v^2 w = uvvw = a^{k+j} b^k\) (man beachte, dass wir \(v = a^j\) ja nun zweimal hintereinander dort stehen haben) und damit ist \(u v^2 w \not\in L\), denn \(j > 1\) und damit haben wir nicht mehr gleiche viele \(a\)s wie \(b\)s. Da die dritte Eigenschaft des Pumping Lemmas aber verlangen würde, dass für jedes \(i \geq 0\) dann \(uv^iw \in L\) ist, haben wir einen Widerspruch. Die ursprüngliche Annahme muss also falsch sein und daher ist \(L\) nicht regulär.
Das notieren von \(v^i\) mit \(i \geq 0\) nennt man Pumpen. Wie die Wahl von \(z\) ist es wieder ein kreativer Prozess, auf ein gutes \(i\) zu kommen, wobei "gut" hier bedeutet ein \(i\) zu finden, das einen Widerspruch erlaubt, mit dem also \(uv^iw \not\in L\) gilt. Es ist manchmal nötig, mehrere Versuche zu unternehmen, bis man auf ein gutes \(z\) und ein gutes \(i\) kommt. Die \(i\) könnten zudem auch unterschiedlich sein, je nachdem welche Zerlegung von \(z\) man hat. Es könnte also sein, dass man die Zerlegung von \(z\) erst geeignet parametrisieren und dann eine Fallunterscheidung machen muss und für unterschiedliche Fälle unterschiedliche \(i\) benötigt. Wichtig ist nur, dass man stets zu einem Widerspruch kommt.
Wir betonen hier auch noch einmal, dass auch \(i = 0\) gesetzt werden darf. Auch das Wort \(uw\) muss also in \(L\) sein und man hat einen Widerspruch, falls dies nicht der Fall ist. Dies ist in machen Fällen die einzige Möglichkeit einen Widerspruch herzustellen, daher sollte man diesen Spezialfall in Erinnerung behalten.
Damit haben wir nun gezeigt, dass es tatsächlich Sprachen gibt, die nicht regulär sind! Wir betonen dies im folgenden Satz.
Satz 2.4.3
Es gibt Sprachen, die nicht regulär sind. Ein Beispiel ist die Sprache \(L := \{a^n b^n \mid n \in \mathbb{N}\}\). Es gibt keinen DFA, der \(L\) akzeptiert.
Das Pumping Lemma hilft uns für Sprachen wie obige und auch für weitere zu zeigen, dass die Sprachen nicht regulär sind. Das Pumping Lemma macht also eine Aussage über eine Eigenschaft, die alle regulären Sprachen haben. Es wird dann aber benutzt, um gerade zu zeigen, dass eine Sprache nicht regulär ist.
Wir fassen noch einmal den Ablauf zusammen, wenn man für eine Sprache \(L\) mittels Nutzung des Pumping Lemmas zeigen will, dass \(L\) nicht regulär ist.
Annehmen \(L\) wäre regulär
Die Zahl aus dem Pumping Lemma benennen (z.B. \(k\)).
Ein Wort \(z\) finden mit \(|z| \geq k\) und \(z \in L\).
Dieses Wort muss gut gewählt sein, damit der nachfolgende Widerspruch gelingt. Hier muss man also u.U. experimentieren.
Für alle Zerlegungen von \(z\) in \(uvw\) zeigen, dass sie
im Widerspruch zur ersten, zweiten oder dritten Bedingung sind.
Üblicherweise betrachtet man alle Zerlegungen, die die erste und zweite Bedingung erfüllen und zeigt, dass man dann einen Widerspruch zur dritten Bedingung erhält.
Also: Alle Zerlegungen \(z = uvw\) mit \(|uv| \leq k\) und \(|v| \geq 1\) betrachten.
Zeigen, dass man ein \(i\) findet mit \(u v^i w \not\in L\). (Dies kann auch \(i = 0\) sein!)
Wir wollen zum Abschluss noch ein zweites Beispiel betrachten und hier beim Beweis zügig vorgehen. Zur Erinnerung: \(w^{rev}\) ist gerade das Wort \(w\) von hinten nach vorne gelesen, also z.B. \(011^{rev} = 110\).
Satz 2.4.4
\(L := \{ w w^{rev} \mid w \in \{0,1\}^* \}\) ist nicht regulär.
Beweis
Angenommen \(L\) wäre regular. Dann gilt das Pumping Lemma. Sei \(k\) die Zahl aus dem Pumping Lemma. Wir betrachten \(z = 0^k 1^k 1^k 0^k\). Es ist \(z \in L\) und \(|z| \geq k\). Sei \(z = uvw\) eine Zerlegung von \(z\) mit \(|uv| \leq k\) und \(|v| \geq 1\). Hieraus folgt \(v = 0^j\) für ein \(j\) mit \(1 \leq j \leq k\). Nun ist aber \(u v^0 w = 0^{k-j} 1^k 1^k 0^k\) nicht mehr in \(L\) im Widerspruch zum Pumping Lemma. Die Annahme ist daher falsch und \(L\) somit nicht regulär.
Man beachte, dass der obige Beweis mit \(z = 0^k 0^k\) nicht gelungen wäre. Die Wahl des Wortes ist also wichtig.
Wir haben in diesem Abschnitt das Pumping Lemma kennengelernt. Dieses macht eine Aussage über die regulären Sprachen, d.h. alle regulären Sprachen haben die im Pumping Lemma beschriebenen Eigenschaften.
Genutzt wird das Pumping Lemma dann, um nachzuweisen, dass eine Sprache nicht regulär ist. Dazu wird gezeigt, dass eine Sprache gerade nicht die im Pumping Lemma beschriebenen Eigenschaften hat. Das Vorgehen ist dabei zu einem gewissen Teil stets gleich. Bei der Wahl des Wortes, das man zerlegen möchte, und bei der Betrachtung aller Zerlegungen und dem Erreichen des Widerspruches ist aber stets Kreativität erforderlich.
Zeitlimit: 0
Quiz-Zusammenfassung
0 von 6 Fragen beantwortet
Fragen:
1
2
3
4
5
6
Informationen
Hier ein paar Fragen zu den Grenzen von regulären Sprachen.
Sie haben das Quiz schon einmal absolviert. Daher können sie es nicht erneut starten.
Quiz wird geladen...
Sie müssen sich einloggen oder registrieren um das Quiz zu starten.
Sie müssen erst folgende Quiz beenden um dieses Quiz starten zu können:
Ergebnis
0 von 6 Frage korrekt beantwortet
Ihre Zeit:
Zeit ist abgelaufen
Sie haben 0 von 0 Punkten erreicht (0)
Kategorien
Nicht kategorisiert0%
1
2
3
4
5
6
Beantwortet
Vorgemerkt
Frage 1 von 6
1. Frage
Für welche Worte \(z\) wird im Pumping Lemma eine Aussage getroffen?
Korrekt
Inkorrekt
Frage 2 von 6
2. Frage
Wie lautet die dritte Eigenschaft im Pumping Lemma?
Korrekt
Inkorrekt
Frage 3 von 6
3. Frage
Welche Formulierung entspricht der dritten Eigenschaft im Pumping Lemma?
Korrekt
Inkorrekt
Frage 4 von 6
4. Frage
Wovon muss das bei einem Widerspruchsbeweis mittels des Pumping Lemmas gewählte Wort \(z\) abhängen?
Korrekt
Inkorrekt
Frage 5 von 6
5. Frage
Wieviele Zerlegungen von \(z\) müssen bei einem Widerspruchsbeweis mittels des Pumping Lemmas betrachtet werden?
Korrekt
Inkorrekt
Frage 6 von 6
6. Frage
Kann mit dem Pumping Lemma gezeigt werden, dass eine Sprache regulär ist?
In diesem Abschnitt wollen wir uns mit Abschlusseigenschaften der regulären Sprachen, d.h. mit der Frage, ob, gegeben eine Operation \(\circ\) und zwei reguläre Sprachen \(L_1, L_2\), auch \(L_1 \circ L_2\) regulär ist. \(\circ\) könnte z.B. die Vereinigung sein oder als Operation auf nur eine Menge, die Operation, die an jedes Wort aus \(L_1\) ein \(a\) anfügt.
Abschlusseigenschaften erlauben oft Einblicke in Sprachfamilien und helfen auch oft beim Konstruieren von z.B. speziellen Automaten oder beim Beweis, dass es keinen Automat für eine Sprache geben kann.
Weitere Formalismen für REG
Bevor wir zu den Abschlusseigenschaften kommen, wollen wir vorher noch zwei weitere Formalismen einführen, die wie DFAs und NFAs gerade die Sprachfamilie der regulären Sprachen erfassen. Wir wollen diese Formalismen nur einführen und benutzen. Die Beweise, dass sie tatsächlich äquivalent zu DFAs sind werden wir nicht führen. Man findet diese Beweise bspw. in dem Buch von Hopcroft, Motwani und Ullman aus der Literaturliste.
NFAs mit \(\lambda\)-Kanten
Man kann einem NFA zusätzlich zu dem bisherigen noch erlauben, \(\lambda\)-Kanten (auch \(\epsilon\)-Kanten genannt) zu benutzen. Diese Kanten sind also statt mit einem Symbol mit dem leeren Wort beschriftet. Die Bedeutung dahinter ist dann auch, dass man nichts vom Eingabeband liest (also quasi das leere Wort vom Eingabeband liest), der Lesekopf auf dem Eingabeband also nicht weiter bewegt wird. Ein Zustandswechsel findet allerdings statt.
In dem abgebildeten Beispiel kann der NFA zuerst ohne ein Symbol zu lesen mittels der \(\lambda\)-Kanten nach \(z_1\) oder \(z_3\) wechseln. Dort arbeitet er dann weiter. Auf dem Wort \(11\) gibt es dann beispielsweise vier verschiedene Rechnungen (in \(z_1\) bleiben, in \(z_3\) bleiben, einmal in \(z_1\) eine \(1\) lesen und dann nach \(z_2\) wechseln und mit der ersten \(1\) nach \(z_2\) wechseln und dort blockieren). Da eine dieser Rechnungen \((z_0, 11) \vdash (z_1, 11) \vdash (z_1, 1) \vdash (z_2, \lambda)\) eine Erfolgsrechnung ist, akzeptiert der NFA. Man beachte, dass bei dem ersten Konfigurationsübergang \((z_0, 11) \vdash (z_1, 11)\) kein Symbol gelesen wird, aber ein Zustandsübergang stattfindet.
Das Beispiel ist zwar recht einfach gewählt, dennoch sollte man sich nicht täuschen lassen. Diese Kanten können äu{\ss}erst nützlich sein. Beim Entwurf von Automaten, erleichtern sie einem wieder an vielen Stellen die Arbeit und bei Beweisen, helfen sie oft Argumente zu vereinfachen.
Man müsste nun noch Begriffe wie Überführungsfunktion, Rechnung, Konfigurationsübergang usw. anpassen. Wir wollen dies hier nicht tun und das Modell einfach informal benutzen. Wir nennen diesen Automaten dann einen NFA mit \(\lambda\)-Kanten oder auch kürzer einen \(\lambda\)-NFA.
Wir betonen noch den folgenden wichtigen Satz:
Satz 2.3.1
Zu jedem \(\lambda\)-NFA \(A\) kann ein DFA \(B\) konstruiert werden mit \(L(B) = L(A)\) und umgekehrt.
Der Satz besagt, dass DFAs, NFAs und \(\lambda\)-NFAs äquivalent sind. Die Familie der regulären Sprachen wird also von jedem dieser drei Modelle erfasst. Auf einen Beweis dieses Satzes wollen wir hier verzichten. Man findet ihn z.B. in dem Buch von Hopcroft, Motwani und Ullman aus der Literaturliste.
Reguläre Ausdrücke
Wir wollen nun noch einen vierten Formalismus einführen, mit dem wir ebenfalls die Familie der regulären Sprachen erfassen. Dies sind die sogenannten regulären Ausdrücke.
Definiton 2.3.2 (Reguläre Ausdrücke)
Sei \(\Sigma\) ein Alphabet. Die regulären Ausdrücke über \(\Sigma\) sind induktiv definiert durch:
\(\emptyset\) ist ein regulärer Ausdruck, der die Menge \(M_{\emptyset} = \emptyset\) beschreibt.
Für jedes \(a \in \Sigma\) ist \(a\) ein regulärer Ausdruck, der die Menge \(M_a = \{a\}\) beschreibt.
Sind \(X\) und \(Y\) reguläre Ausdrücke, die die Mengen \(M_X\) und \(M_Y\) beschreiben, dann beschreibt
\((X + Y)\) die Menge \(M_X \cup M_Y\)
\((X \cdot Y)\) die Menge \(M_X \cdot M_Y\)
\(X^*\) die Menge \(M_X^*\) und
\(X^+\) die Menge \(M_X^+\).
Nur die so erzeugten (endlichen) Ausdrücke sind reguläre Ausdrücke.
Ein paar Beispiele für reguläre Ausdrücke, wobei \(\equiv\) hier für „beschreibt die Menge“ steht:
Worte, die \(00\) oder \(11\) enthalten: \((0+1)^* \cdot (00 + 11) \cdot (0+1)^*\)
Reguläre Ausdrücke und die Mengenoperationen sind also recht ähnlich. Mit regulären Ausdrücken spart man sich aber oft eine Menge Klammern. Daneben wollen wir auch die üblichen Regeln zur Klammerersparnis nutzen wie \(\cdot\) vor \(+\) und die hochgestellten \(+\) und \(*\) vor \(\cdot\).
Aufgrund der Ähnlichkeit, wollen wir dann reguläre Ausdrücke gleich wie Mengen nutzen und z.B. \(aaa \in a^*\) erlauben. Gemeint ist dann mit dem regulären Ausdruck in diesem Kontext gerade die Menge, die er beschreibt.
Man kann nun wieder zeigen, dass es zu jedem regulären Ausdruck \(R\) einen DFA \(A\) gibt, der gerade die von \(R\) beschriebene Menge akzeptiert und dass es zu jedem DFA \(A\) eine regulären Ausdruck gibt, der gerade \(L(A)\) beschreibt. Auch hier wollen wir reguläre Ausdrücke der Definition entsprechend benutzen, den eben angesprochenen Beweis jedoch nicht führen. Er findet sich wieder in der Literatur.
Insgesamt haben wir damit folgenden Satz:
Satz 2.3.3
Zu jeder regulären Sprache \(L\) gibt es
einen DFA \(A\) mit \(L(A) = L\)
einen NFA \(B\) mit \(L(B) = L\)
einen NFA mit \(\lambda\)-Kanten \(C\) mit \(L(C) = L\)
einen regulären Ausdruck \(D\), der \(L\) beschreibt (\(M_D = L\))
DFAs, NFAs, NFAs mit \(\lambda\)-Kanten und reguläre Ausdrücke sind also äquivalent.
Abschlusseigenschaften
Wir wollen uns nun damit beschäftigen, ob die regulären Sprachen gegenüber bestimmten Operationen abgeschlossen sind. Betrachten wir als Operation z.B. die Vereinigung, dann interessiert uns die Frage, ob \(L_1 \cup L_2 \in REG\) ist, wenn \(L_1, L_2 \in REG\) gilt. Gilt dies stets, so sagt man die Sprachfamilie der regulären Sprachen ist gegenüber Vereinigung abgeschlossen. Die Bezeichnung rührt daher, dass man mittels dieser Operation dann quasi nicht aus der Familie der regulären Sprachen herauskommt.
Um den Abschluss genauer zu formulieren, definieren wir:
Definiton 2.3.4 (Reguläre Ausdrücke)
Sei \(f_1\) eine einstellige Operation auf Mengen und \(f_2\) eine zweistellige Operationen. D.h. wenn \(M_1, M_2\) zwei Mengen sind, dann sind auch \(f_1(M_1)\) und \(f_2(M_1, M_2)\) Mengen.
Eine Sprachfamilie \(\mathcal{C}\) ist abgeschlossen gegenüber der Operation \(f_1\) bzw. \(f_2\), wenn für jedes \(R \in \mathcal{C}\) auch \(f_1(R) \in \mathcal{C}\) gilt bzw. wenn für \(R_1, R_2 \in \mathcal{C}\) auch \(f_2(R_1, R_2) \in \mathcal{C}\) gilt.
Man kann dies auch allgemeiner für Mengen und Operationen auf diesen Mengen einführen. Die Menge der natürlichen Zahlen ist dann z.B. gegenüber der Addition abgeschlossen, da die Summe zweier natürlicher Zahlen wieder eine natürliche Zahl ist. Die natürlichen Zahlen sind hingegen nicht gegenüber der Subtraktion abgeschlossen, da es zwar natürliche Zahlen gibt, die subtrahiert voneinander wieder eine natürliche Zahl ergeben, aber eben auch welche, bei denen das nicht passiert (wobei es hier primär auf die Reihenfolge ankommt, aber die dürfte man sich ja auch nicht aussuchen, sonst hätte man eine andere Operation).
Einfache Abschlusseigenschaften
Wir wollen nun für einige Operationen zeigen, dass die regulären Sprachen gegenüber ihnen abgeschlossen sind. Die ersten vier Operationen kriegen wir fast geschenkt.
Satz 2.3.5
Die regulären Sprachen sind gegenüber \(\cup, \cdot, +, *\) abgeschlossen.
Beweise
Seien \(L_1, L_2 \in \text{REG}\). Dann gibt es reguläre Ausdrücke \(A_1, A_2\), die \(L_1\) bzw. \(L_2\) beschreiben. Nach Definition der regulären Ausdrücke sind nun auch \(A_1 + A_2\), \(A_1 \cdot A_2\), \(A_1^+\), \(A_1^*\) reguläre Ausdrücke. Diese beschreiben gerade die Mengen \(L_1 \cup L_2\), \(L_1 \cdot L_2\), \(L_1^+\) und \(L_1^*\), die aufgrund des Satzes zur Äquivalenz regulärer Ausdrücke und DFAs wieder regulär sind.
Wir haben für diese vier Operationen also gar nicht viel zu tun gehabt. Wir müssen hier lediglich beachten, dass jede durch einen regulären Ausdruck beschriebene Menge eine reguläre Sprache ist. Dann benutzen wir noch die Operationen, die wir bei regulären Ausdrücken syntaktisch haben und sind schon fertig.
Komplementbildung
Schwieriger ist da schon zu zeigen, dass die regulären Sprachen gegenüber Komplementbildung abgeschlossen sind.
Definiton 2.3.6
Sei \(L \subseteq \Sigma^*\). Dann ist $$ \overline{L} = \{w \in \Sigma^* \mid w \not\in L\} $$ das Komplement von \(L\).
In \(\overline{L}\) sind also gerade all jene Worte aus \(\Sigma^*\), die nicht in \(L\) sind. Die Worte, die in \(L\) sind, sind gerade nicht in \(\overline{L}\).
Sind die regulären Sprachen nun gegenüber Komplementbildung abgeschlossen? Wir können zumindest nicht so vorgehen wie bei dem vorherigen Satz. Dort nutzten wir reguläre Ausdrücke. Das ist hier nicht so leicht möglich, da sich in der Definition der regulären Ausdrücke keine Operation findet, mit der wir Komplement ausdrücken könnten.
Pause to Ponder: Geht das also? Sind die regulären Sprachen gegenüber Komplementbildung abgeschlossen? Man versuche das statt mit regulären Ausdrücken mit den Automaten zu zeigen, d.h. man geht von einem Automaten \(A\) für eine reguläre Sprache \(L\) aus und konstruiert daraus einen Automaten \(A‘\) für \(\overline{L}\). Aber wie?
Mit regulären Ausdrücken kommen wir tatsächlich nicht gut weiter. Wohl aber mit Automaten! Haben wir einen Automaten \(A\) für eine Sprache \(L\), dann wollen wir jetzt also erreichen, dass ein Wort, das \(A\) akzeptiert hat, nicht mehr akzeptiert wird und ein Wort, das \(A\) nicht akzeptiert hat, nun akzeptiert wird. Dies erreichen wir gerade, indem wir Zustände, die keine Endzustände sind, zu solchen machen und umgekehrt. Endeten wir dann vorher in einem normalen Zustand (und akzeptierten also nicht), so enden wir jetzt in einem Endzustand (und akzeptieren also), endeten wir vorher in einem Endzustand (und akzeptierten also), so enden wir nun in einem normalen Zustand (und akzeptieren also nicht). Auf eine Kleinigkeit müssen wir noch achten. Damit dies funktioniert, muss \(A\) auch tatsächlich jedes Wort lesen können. Kann er ein Wort nämlich nicht zu Ende lesen, so wird das Wort nicht akzeptiert. Unser neuer Automat kann das Wort dann aber weiterhin nicht zu Ende lesen und akzeptiert also auch nicht. Wir müssen also dafür sorgen, dass \(A\) jedes Wort lesen kann. Dies erreichen wir ganz einfach dadurch, dass wir gleich zu Beginn von einem vollständigen DFA \(A\) für \(L\) ausgehen, der ja ebenfalls stets existiert. Wir fassen den Beweis noch einmal zusammen.
Satz 2.3.7
Die regulären Sprachen sind gegenüber Komplementbildung abgeschlossen, d.h. ist \(L \in \text{REG}\), dann auch \(\overline{L} \in \text{REG}\).
Beweise
Sei \(L \in \text{REG}\). Dann gibt es einen vollständigen DFA \(A\) mit \(L(A) = L\). Wir konstruieren nun einen vollständigen DFA \(A‘\) aus \(A\) wie folgt:
Zunächst übernehmen wir alles von \(A\).
Ist dann \(z \in Z\) in \(A\) Endzustand, dann ist \(z\) in \(A‘\) kein Endzustand.
Ist \(z \in Z\) in \(A\) kein Endzustand, dann ist \(z\) in \(A‘\) ein Endzustand.
Wir tauschen also lediglich End- und Nicht-Endzustände.
Wurde ein Wort \(w\) nun von \(A\) akzeptiert, dann gab es eine Rechnung \((z_0, w) \vdash (z_e, \lambda)\), wobei \(z_e\) ein Endzustand von \(A\) ist. Diese Rechnung passiert nun genauso auch in \(A‘\) nur ist dort \(z_e\) kein Endzustand und folglich wird \(w\) von \(A‘\) nicht akzeptiert.
Wurde andererseits ein Wort von \(A\) nicht akzeptiert, dann gab es eine Rechnung \((z_0, w) \vdash (z, \lambda)\), wobei \(z\) kein Endzustand von \(A\) ist. Man beachte an dieser Stelle, dass \(A\) vollständig ist. Der Fall, dass ein Wort nicht akzeptiert wird, weil es nicht zu Ende gelesen wird, tritt also nicht auf. Die obige Rechnung passiert nun wieder genauso in \(A‘\), nur ist dort \(z\) ein Endzustand und folglich wird \(w\) von \(A‘\) akzeptiert.
Man beachte, dass es uns völlig frei steht, mit welcher Darstellung für die reguläre Sprache \(L\) wir starten. Wichtig ist nur, dass diese Darstellung tatsächlich \(L\) beschreiben kann, also entweder ein DFA ist oder ein NFA, ein \(\lambda\)-NFA, ein regulärer Ausdruck oder eben ein DFA, der zudem noch vollständig ist. Da all diese Formalismen die regulären Sprachen erfassen, gibt es zu jeder regulären \(L\) Sprache auch z.B. einen DFA mit \(L(A) = L\) oder einen regulären Ausdruck \(R\) mit \(M_R = L\).
Wir können hier also frei wählen, womit wir starten wollen und können dann diese Darstellung manipulieren, also z.B. bei einem Automaten Zustände oder Kanten hinzufügen, Kanten umbiegen oder eben Endzustände manipulieren. Wichtig ist dann, dass bei diesen Manipulationen etwas entsteht, von dem wir dann zeigen können, dass wir damit unser Ziel erreichen. Oben musste also ein Automat entstehen, der gerade \(\overline{L}\) akzeptiert.
Durchschnittsbildung
Als nächstes wenden wir uns dem Durchschnitt oder dem Produkt zweier Sprachen zu, d.h. der Operation \(L_1 \cap L_2\).
Pause to Ponder: Sind \(L_1\) und \(L_2\) regulär, ist dann auch \(L_1 \cap L_2\) regulär?
Dies lässt sich mit unserem bisherigen Wissen sehr schnell zeigen. Wenn man bedenkt, dass \(L_1 \cap L_2 = \overline{\overline{L_1} \cup \overline{L_2}}\) nach dem Gesetz von de Morgan gilt, dann sind wir sofort fertig, da wir ja schon wissen, dass die regulären Sprachen gegenüber Komplement und Vereinigung abgeschlossen sind. (Sind also \(L_1\) und \(L_2\) regulär, dann ist auch \(\overline{L_1}\) und \(\overline{L_2}\) und damit auch \(\overline{L_1} \cup \overline{L_2}\) und damit letztendlich \(\overline{\overline{L_1} \cup \overline{L_2}}\) regulär, was gerade \(L_1 \cap L_2\) ist.)
Es gibt aber eine sehr schöne Methode, wie man dies direkt mit Automaten machen kann. Wir wollen dies hier einmal tun und dabei den Produktautomaten zu zwei Automaten \(A_1\) und \(A_2\) kennenlernen. Dieser akzeptiert gerade dann ein Wort, wenn \(A_1\) und \(A_2\) dieses Wort beide akzeptieren. Damit akzeptiert der Produktautomat also gerade den Schnitt von \(L(A_1)\) und \(L(A_2)\).
Pause to Ponder: Wie lässt sich aus einem endlichen Automaten \(A_1\) für \(L_1\) und einem endlichen Automaten \(A_2\) für \(L_2\) ein Automat \(C\) für \(L_1 \cap L_2\) konstruieren?
Erinnern wir uns an die Potenzautomatenkonstruktion. Hier haben wir uns im Zustand des konstruierten DFAs gemerkt, in welchen Zuständen der ursprüngliche NFA nichtdeterministisch sein kann. Hier können wir ähnlich vorgehen. Allerdings wollen wir uns genau merken, welcher Zustand zum ersten und welcher Zustand zum zweiten Automaten gehört. Wir arbeiten daher mit Tupeln \((z_1, z_2)\) als neue Zustände von \(C\), wobei im ersten Tupelelement ein Zustand von \(A_1\) und im zweiten Tupelelement ein Zustand von \(A_2\) notiert wird. Ein Übergang mit Symbol \(a\) geschieht dann genau dann, wenn im ersten Tupelelement (also im Automaten \(A_1\)) ein Übergang mit \(a\) möglich ist und ebenso im zweiten Tupelelement (also im Automaten \(A_2\)). Wenn \(C\) dann ein Wort \(w\) liest, dann macht er im ersten Tupelelement seiner Zustände quasi eine Rechnung von \(A_1\) und im zweiten eine von \(A_2\). Akzeptieren soll er daher genau dann, wenn im ersten Tupelelement ein Endzustand von \(A_1\) und im zweiten Tupelelement ein Endzustand von \(A_2\) ist. So ist sichergestellt, dass beide Automaten gleichzeitig in einem Endzustand sind, also beide das Wort \(w\) akzeptieren. Dies ist gerade, was wir für \(C\) erreichen wollen. \(C\) soll akzeptieren, wenn \(A_1\) \emph{und} \(A_2\) akzeptieren und sonst ablehnen. Wir formalisieren die Konstruktion jetzt genauer.
Satz 2.3.8
Seien \(L_1, L_2 \in \text{REG}\), dann ist auch \(L_1 \cap L_2 \in \text{REG}\).
Beweise
Seien \(A_1 = (Z_1, \Sigma_1, \delta_1, z_{1,0}, Z_{1, end})\) und \(A_2 = (Z_2, \Sigma_2, \delta_2, z_{2,0}, Z_{2, end})\) vollständige DFAs mit \(L(A_1) = L_1\) und \(L(A_2) = L_2\). Wir konstruieren \(C = (Z_3, \Sigma_3, \delta_3, z_{3,0}, Z_{3,end})\) mit
Da \(A_1\) und \(A_2\) vollständig sind, ist jeder Zustandsübergang in \(C\) definiert.
Hat man nun eine Rechnung $$ (z_{1,0}, z_{2,0}, w_1 w_2 w_3 \ldots) \vdash ((z_1, z_2), w_2 w_3 \ldots) \vdash ((z_1′, z_2′), w_3 \ldots) \vdash \ldots $$ von \(C\), so ist \((z_{1,0}, w_1 w_2 w_3 \ldots) \vdash (z_1, w_2 w_3 \ldots) \vdash (z_1′, w_3 \ldots) \vdash \ldots\) eine Rechnung von \(A_1\) und ebenso \((z_{2,0}, w_1 w_2 w_3 \ldots) \vdash (z_2, w_2 w_3 \ldots) \vdash (z_2′, w_3 \ldots) \vdash \ldots\) eine von \(A_2\). Zumindest wollen wir dies mit der Konstruktion erreichen. Wir formulieren dies daher als eine Behauptung. Man beachte, dass mit \(A_1\) und \(A_2\) auch \(C\) vollständig ist, daher kann jedes Wort gelesen werden. Wir behaupten nun, dass für jedes Wort \(w \in \Sigma_3^*\) gilt: $$ \hat{\delta_3}(z_{3,0}, w) = (z_1, z_2) \Leftrightarrow
\hat{\delta_1}(z_{1,0}, w) = z_1 \wedge
\hat{\delta_2}(z_{2,0}, w) = z_2 $$ Wir behaupten also, wenn \(C\) nach Lesen von \(w\) in \((z_1, z_2)\) ist, dann ist \(A_1\) nach Lesen von \(w\) in \(z_1\) und \(A_2\) nach Lesen von \(w\) in \(z_2\) und wenn umgekehrt \(A_1\) nach Lesen von \(w\) in \(z_1\) und \(A_2\) nach Lesen von \(w\) in \(z_2\) ist, dann ist \(C\) nach Lesen von \(w\) in \((z_1, z_2)\). Dies ist genau das, was wir uns als Ziel unserer Konstruktion überlegt hatten und dies kann man recht schnell mittels Induktion über die Wortlänge beweisen.
Im Anschluss folgt dann schnell die Korrektheit der Konstruktion, weil nach Definition der Endzustandsmenge von \(C\) dann aus obigem $$ \hat{\delta_3}(z_{3,0}, w) \in Z_{3,end} \Leftrightarrow
\hat{\delta_1}(z_{1,0}, w) \in Z_{1,end} \wedge
\hat{\delta_2}(z_{2,0}, w) \in Z_{2,end} $$ folgt, womit gezeigt ist, dass \(C\) ein Wort \(w\) genau dann akzeptiert, wenn \(w\) von \(A_1\) und von \(A_2\) akzeptiert wird, d.h. es ist \(L(C) = L(A_1) \cap L(A_2)\).
Den Induktionsbeweis oben wollen wir zur Übung überlassen. Man kann sich hierfür gut an den Induktionsbeweisen, die wir bisher hatten, orientieren.
Noch eine Anmerkung zur Konstruktion: Wenn man den Produktautomaten konstruieren will (oder einen Algorithmus dafür implementieren will), dann verfährt man wieder so wie beim Potenzautomaten und beginnt nicht sofort mit \(Z_3 = Z_1 \times Z_2\), sondern beginnt mit dem Startzustand \(z_{3,0} = (z_{1,0}, z_{2,0})\) und konstruiert dann sukzessive die initiale Zusammenhangskomponente.
Spiegelworte
Zuletzt wollen wir einen Blick auf Spiegelworte werfen. Spiegelworte sind Worte, die sich durch rückwärts Lesen eines ursprünglichen Wortes ergeben. Ist z.B. \(w = 011\), dann ist das Spiegelwort \(w^{rev} = 110\). Wir definieren dies formal mittels einer induktiven Definition.
Definiton 2.3.9
Das Spiegelwort \(w^{rev}\) zu einem Wort \(w \in \Sigma^*\) ist definiert durch
\(\lambda^{rev} = \lambda\) und
\((ux)^{rev} = x \cdot u^{rev}\) mit \(x \in \Sigma\) und \(u \in \Sigma^*\)
Bspw. ist für \(w = 1011\) dann \(w^{rev} = 1101\).
Für Mengen notieren wir \(L^{rev} = \{ w^{rev} \mid w \in L\}\).
Intuitiv ist die Bedeutung von \(w^{rev}\) vermutlich schnell klar. Die Definition steht hier insb. aufgrund ihres Charakters: Zuerst wird die Bedeutung von \(rev\) für das leere Wort definiert. Im Anschluss wird die Bedeutung für längere Worte mittels der Bedeutung von \(rev\) für kürzere Worte definiert. Genau auf diese Art und Weise gehen wir auch immer bei induktiven Beweisen über die Wortlänge vor. Zunächst haben wir den Fall des leeren Wortes, dann den eines längeren Wortes, wobei wir die Induktionsannahme für kürzere Worte benutzen. Die Induktionsannahme entspricht hier der Definition für kürzerer Worte (also oben beim zweiten Punkte dem \(u\)).
Wir können nun zeigen, dass die regulären Sprachen gegenüber der \(rev\)-Operation abgeschlossen sind.
Satz 2.3.10
Ist \(L\) regulär, dann ist auch \(L^{rev}\) regulär.
Beweise
Wir wollen den Beweis hier nur skizzieren. Wir gehen wieder von einem vollständigen DFA \(A\) für \(L\) aus. Die Worte aus \(L^{rev}\) sind gerade die Worte, die in einem Endzustand beginnen und in einem Startzustand enden, wenn man die Kanten rückwärts entlang geht. Wir konstruieren daher aus \(A\) einen NFA \(B\), indem wir alle Kanten in \(A\) umdrehen, den Start- zu einem Endzustand machen und alle Endzustände zu Startzuständen.
Um noch zu zeigen, dass \(L(B) = L(A)^{rev}\) gilt, kann man einfach akzeptierende Rechnungen des einen Automaten nehmen und zeigen, dass der jeweils andere Automat eine Erfolgsrechnung mit dem gleichen, aber umgedrehten, Weg im Zustandsdiagramm hat.
Mit diesem Resultat können wir dann endlich auch schlussfolgern, dass die komplizierte Sprache $$ Sum = \{ w \in \Sigma^* \mid \text{ die unterste Zeile ist Summe der oberen Zeilen} \} $$ tatsächlich regulär ist (zur Erinnerung: die Symbole in \(\Sigma\) waren im Grunde Vektoren der Länge \(3\) also z.B. \((0,0,1)\) als Spalte geschrieben). Bisher hatten wir ja nur gezeigt, dass \(Sum^{rev}\) regulär ist.
Wir haben in diesem Abschnitt \(\lambda\)-NFAs kennengelernt, also NFAs, die zusätzlich \(\lambda\)-Kanten benutzen können. Bei \(\lambda\)-Kanten wird kein Buchstabe gelesen. Es findet aber ein Zustandswechsel statt.
Ferner haben wir reguläre Ausdrücke kennengelernt, also Ausdrücke der Art \((a+b)^* \cdot a^+\).
Von beiden Formalismen nehmen wir mit, dass sie äquivalent zu DFAs sind. Wir kennen damit nun vier Formalismen, die die Familie der regulären Sprachen erfassen: DFAs, NFAs, \(\lambda\)-NFAs und reguläre Ausdrücke.
Im Anschluss haben wir uns dann mit Abschlusseigenschaften beschäftigt. Hierbei geht es darum für zwei Sprachen \(L_1, L_2\) einer Sprachfamilie und eine Operation \(\circ\) zu zeigen, dass auch \(L_1 \circ L_2\) in dieser Sprachfamilie ist (oder auch ein Gegenbeispiel anzugeben, um dies zu widerlegen).
Wir haben gesehen, dass die regulären Sprachen gegenüber \(\cup, \cdot, + , *\), Komplementbildung, Durchschnitt und \(rev\) abgeschlossen sind. Bei den ersten vier haben wir in den Beweisen mit regulären Ausdrücken argumentiert, bei den letzten drei mit (vollständigen) DFAs. Hier hat man also stets eine Wahlfreiheit und kann den Formalismus nehmen, der einem am geeignetsten erscheint. Dies ist auch einer der Gründe, warum unterschiedliche Formalismen eingeführt werden und selbst nachdem man gezeigt hat, dass sie äquivalent zu schon bestehenden sind, weiterhin benutzt werden. Oft beleuchten unterschiedliche Formalismen Dinge nämlich von unterschiedlichen Blickwinkeln.
Zeitlimit: 0
Quiz-Zusammenfassung
0 von 4 Fragen beantwortet
Fragen:
1
2
3
4
Informationen
Hier ein paar Fragen zu Abschlusseigenschaften.
Sie haben das Quiz schon einmal absolviert. Daher können sie es nicht erneut starten.
Quiz wird geladen...
Sie müssen sich einloggen oder registrieren um das Quiz zu starten.
Sie müssen erst folgende Quiz beenden um dieses Quiz starten zu können:
Ergebnis
0 von 4 Frage korrekt beantwortet
Ihre Zeit:
Zeit ist abgelaufen
Sie haben 0 von 0 Punkten erreicht (0)
Kategorien
Nicht kategorisiert0%
1
2
3
4
Beantwortet
Vorgemerkt
Frage 1 von 4
1. Frage
Sei \(R = 0^* \cdot 1^+ \cdot (0+1)^*\). In welchen Fällen ist\($w_1 \in M_R\) und \(w_2 \not\in M_R\)?
Korrekt
Inkorrekt
Frage 2 von 4
2. Frage
Welcher reguläre Ausdruck beschreibt die Menge \(\overline{\{a\}^*}\)?
Korrekt
Inkorrekt
Frage 3 von 4
3. Frage
Sind die regulären Sprachen gegenüber Vereinigung abgeschlossen?
Korrekt
Inkorrekt
Frage 4 von 4
4. Frage
Welcher reguläre Ausdruck beschreibt die Menge jener Worte, bei denen auf eine \(0\) stets eine \(1\) folgt?
Nachdem wir den NFA nun eingeführt haben, macht es Sinn, dass wir uns als nächstes gleich die Frage stellen, in welchem Verhältnis er zum DFA steht? Kann der DFA mehr als der NFA? Kann der NFA mehr als der DFA? Können beide das gleiche? Sind sie unvergleichbar?
Mehr zu „können“ bezieht sich hierbei auf die akzeptierten Sprachen. Der NFA kann dann mehr als der DFA, wenn es zu jeder Sprache \(M\), zu der es einen DFA gibt, der \(M\) akzeptiert, auch einen NFA gibt, der \(M\) akzeptiert, und ferner, wenn es eine Sprache \(M‘\) gibt, für die zwar ein NFA konstruiert werden kann, aber kein DFA.
Pause to Ponder: Welcher Automat ist mächtiger? DFA oder NFA? Oder sind sie gleich mächtig? Oder unvergleichbar?
Was man recht schnell sehen kann, ist, dass jeder DFA auch als spezieller NFA angesehen werden kann, der NFA also mindestens all das kann, was der DFA kann. Seine spezielle Fähigkeit zu einem Buchstaben mehrere Kanten aus einem Zustand heraus zu haben, brauch der NFA ja gar nicht benutzen und ist dann im Grunde ein DFA. Will man dies formal ausführen, so sei \(\delta_D\) die Überführungsfunktion eines DFA und \(z_0\) sein Startzustand. Man setzt dann $$ \delta_N(z,x) := \{\delta_D(z,x)\} $$und $$ Z_{start} := \{z_0\} $$für die Überführungsfunktion \(\delta_N\) und die Startzustandsmenge \(Z_{start}\) des NFA. Zustandsmenge, Eingabealphabet und Endzustandsmenge übernimmt man für den NFA. Ist \(A\) der DFA und \(B\) der so konstruierte NFA, so kann man \(L(A) = L(B)\) sehr einfach zeigen, da im Grunde genau das gleiche passiert, nur das in der erweiterten Überführungsfunktion im ersten Argument einmal ein Zustand steht (beim DFA) und einmal eine einelementige Menge mit gerade diesem Zustand (beim NFA).
Die spannende Frage ist nun also, ob es auch andersherum geht, ob man also zu jedem NFA \(A\) einen DFA \(B\) konstruieren kann mit \(L(A) = L(B)\) oder ob es eine Sprache gibt, die ein NFA akzeptieren kann, aber kein DFA.
Pause to Ponder: Hier daher noch einmal eine Pause. Ist der NFA mächtiger? Falls ja, mit welcher Sprache könnte man dies eventuell zeigen? Oder kann man zu jedem NFA einen DFA konstruieren, der die gleiche Sprache akzeptiert? Falls ja, was könnte hier die Idee sein?
Wenn wir noch einmal die Arbeitsweise des NFA betrachten, dann stellen wir fest, dass der NFA stets (nichtdeterministisch) in einer Menge von Zuständen sein kann, also in einer Teilmenge seiner Zustandsmenge. Dies erkennt man auch gut an der erweiterten Überführungsfunktion, bei der im ersten Argument ja gerade diese Menge an Zuständen gesammelt wird.
Sei \(Z\) die Zustandsmenge des NFA, dann gibt es gerade \(2^{|Z|}\) viele Teilmengen von \(Z\). Dies sind zwar recht viele, aber es sind endlich viele! Erinnern wir uns an die Konstruktionsmethoden für DFAs, so könnte ein vielversprechender Ansatz also sein, sich in den Zuständen des DFAs gerade diese Teilmengen der Zustände des NFAs zu merken. Die Übergänge könnten dann gerade so gelingen, wie wir dies beim NFA machen, soll heißen: Wenn wir beim NFA \(\hat{\delta}(M,xw) = \hat{\delta}(M‘,w)\) haben, so wechseln wir im DFA aus dem Zustand, in dem wir uns gemerkt haben, dass der NFA nichtdeterministisch in den Zuständen aus \(M\) ist, nun in den Zustand, in dem wir uns dies für \(M‘\) merken. Genau dies passiert ja beim NFA. Vor dem Lesen von \(x\) ist er nichtdeterministisch in den Zuständen aus \(M\), danach nichtdeterministisch in den Zuständen aus \(M‘\). Diese Übergänge lassen sich dann also durch die Überführungsfunktion des NFA ermitteln.
Als Startzustand macht dann die Menge der Startzustände des NFA Sinn, denn in diesen Zuständen ist der NFA ja zu Anfang nichtdeterministisch. Bleibt die Endzustandsmenge zu definieren. Da wir im NFA dann akzeptieren, sobald in der Menge, in der der NFA sich nichtdeterministisch befindet, am Ende ein Endzustand ist, könne wir versuchen im DFA all jene Zustände zu Endzuständen zu machen, in denen wir uns eine Menge \(M\) merken, in der gerade ein Endzustand ist.
Mit diesen Überlegungen können wir zu jedem NFA einen DFA konstruieren und tatsächlich kann man beweisen, dass diese Konstruktion das Gewünschte leistet. Wir fassen die Konstruktion nun noch einmal formal zusammen, machen dann ein Beispiel und zeigen dann, dass die Konstruktion korrekt ist.
Satz 2.2.5
Zu jeder von einem NFA \(A\) akzeptierte Menge \(L\) kann ein DFA \(B\) konstruiert werden mit \(L(B) = L\).
Beweis
Wir geben zunächst die oben bereits intuitiv beschriebene Konstruktion an. Sei dazu \(A = (Z, \Sigma, \delta, Z_{start}, Z_{end})\) ein NFA. Wir definieren einen DFA \(B = (Z‘, \Sigma‘, \delta‘, z_0, Z_{end}‘)\) wie folgt:
\(Z‘ := 2^Z\)
\(\Sigma‘ := \Sigma\)
\(\delta'(M,x) := \cup_{z \in M} \delta (z,x)\) oder alternativ
\(\delta'(M,x) := \cup_{z \in M} \{z‘ \in Z \mid (z,x,z‘) \in K\}\)
Bevor wir beweisen, dass diese Konstruktion korrekt ist, dass also tatsächlich \(L(B) = L(A)\) gilt, führen wir die Konstruktion an einem Beispiel aus. Im Anschluss setzen wir den Beweis dann fort.
Betrachten wir die formale Konstruktion noch einmal. Die Menge der Zustände \(Z'\) des DFA ist gerade die Menge aller Teilmengen der Zustandsmenge \(Z\) des NFA. Ist also z.B. \(\{z_0, z_1\} \subseteq Z\), so ist diese Menge von Zuständen des NFA nun ein einzelner Zustand des DFA. Das Eingabealphabet wurde einfach übernommen, da ja weiterhin die gleichen Symbole gelesen werden sollen. Der Startzustand des DFA ist gerade die Menge der Startzustände des NFA (denn in einem dieser Zustände startet ja jede Rechnung des NFA) und die Endzustände des DFA sind all jene Mengen von Zuständen des NFA, die mindestens einen Endzustand des NFA enthalten (denn endet eine Rechnung des NFA in einem Endzustand, d.h. befindet sich in der Menge der Zustände, in denen er sich nichtdeterministisch nach Lesen eines Eingabewortes befindet, ein Endzustand, so akzeptiert er und dann soll auch der DFA akzeptieren). Um die Überführungsfunktion des DFA zu definieren, werden alle Zustände in der aktuellen Menge \(M\) für ein Symbol \(x\) durchgegangen und für jeden dieser Zustände die Menge der möglichen Nachfolgezustände im NFA ermittelt. Alle diese Mengen werden dann vereinigt und ergeben den Nachfolgezustand im DFA.
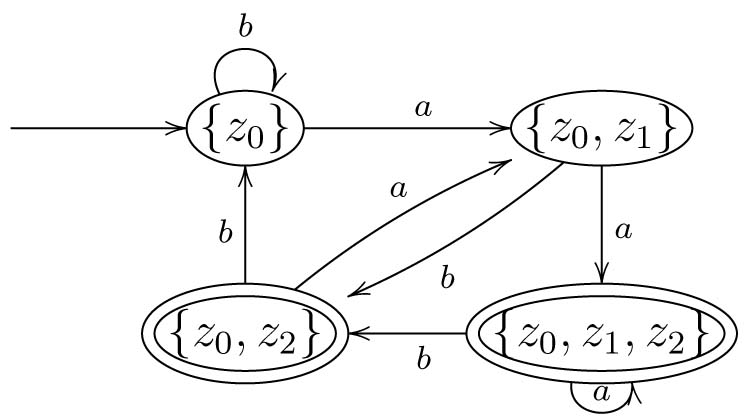
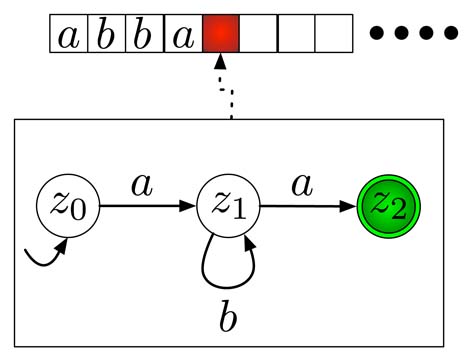
Betrachten wir als Beispiel den gezeigten NFA.
Um den DFA zu konstruieren, genügt es, die initiale Zusammenhangskomponente zu bestimmen, d.h. wir beginnen beim Startzustand des DFA und konstruieren für jedes Symbol \(x \in \Sigma\) die Nachfolgezustände. Bei diesen machen wir dann so lange weiter, bis keine neuen Zustände mehr generiert werden. Wir beginnen also mit dem Startzustand \(z_0 := Z_{start}\).
Wir wählen nun den Zustand \(\{z_0\}\) des DFA und gehen alle Zustände der Menge durch (hier ist dies zunächst nur der Zustand \(z_0\)). Dann ermitteln wir für das erste Symbol (z.B. \(a\)) die Nachfolgezustände im NFA. Wegen \(\delta(z_0,a)= \{z_0, z_1\}\) ist dies die Menge \(\{z_0,z_1\}\), die dann also der Nachfolgezustand von \(\{z_0\}\) im DFA ist. Entsprechend gelangen wir mit \(b\) zu \(\{z_0\}\).
Mit dem Zustand \(\{z_0\}\) sind wir nun fertig, aber wir haben einen neuen Zustand generiert und machen mit diesem wie eben weiter. Wir halten also ein Symbol \(x\) des Eingabealphabets fest, gehen dann bei \(\{z_0,z_1\}\) alle Zustände durch, ermitteln im NFA die Menge der Nachfolgezustände von \(x\), also \(\delta(z_0,x)\) und \(\delta(z_1,x)\), und vereinigen diese Mengen. Die sich so ergebene Menge ist der Nachfolgezustand im DFA für das Symbol \(x\).
Wegen \(\delta(z_0, a) = \{z_0, z_1\}\) und \(\delta(z_1, a) = \{z_2\}\) ergibt sich \(\delta'(\{z_0, z_1\},a) = \{z_0, z_1, z_2\}\). Für \(b\) ergibt sich analog \(\delta'(\{z_0, z_1\},b) = \{z_0, z_2\}\).
Wir haben nun also zwei neue Zustände erzeugt und verfahren mit diesen nun wie eben weiter.
Für den Zustand \(\{z_0, z_2\}\) ergibt sich wegen \(\delta(z_0, b) = \{z_0\}\) und \(\delta(z_2, b) = \emptyset\) dann \(\delta'(\{z_0, z_2\},b) = \{z_0\}\) und wegen \(\delta(z_0, a) = \{z_0, z_1\}\) und \(\delta(z_2, a) = \emptyset\) dann \(\delta'(\{z_0, z_2\},a) = \{z_0, z_1\}\).
Für \(\{z_0, z_1, z_2\}\) ergibt sich wegen \(\delta(z_0, b) = \{z_0\}\), \(\delta(z_1, b) = \{z_2\}\) und \(\delta(z_2, b) = \emptyset\) dann \(\delta'(\{z_0, z_1, z_2\},b) = \{z_0, z_2\}\) und analog für \(\delta'(\{z_0, z_1, z_2\},a) = \{z_0, z_1, z_2\}\).
Wir haben nun für jeden Zustand für jedes Symbol Kanten und sind damit mit der Konstruktion (fast) fertig. Die Endzustände fehlen uns nun noch. Nach der Konstruktion werden all jene Zustände des DFA zu Endzuständen, die mindestens einen Endzustand des NFA enthalten. Dies sind hier gerade \(\{z_0, z_2\}\) und \(\{z_0, z_1, z_2\}\), da nur diese den einzigen Endzustand \(z_2\) des NFA enthalten. Damit ergibt sich letztendlich der rechts abgebildete Automat.
Dies schließt die Konstruktion ab. Wir hätten streng nach der angegebenen Konstruktion noch weitere Zustände konstruieren müssen, die aber für die akzeptierte Sprache nicht von Bedeutung sind, da sie vom Startzustand aus nicht erreicht werden können. Wir kommen auf diesen Unterschied später noch einmal zu sprechen.
Beweis (Fortsetzung)
Nach diesem Beispiel setzen wir den Beweis nun fort. Wir wollen jetzt \(L(A) = L(B)\) zeigen. Da wir dies gleich im Beweis brauchen werden, wiederholen wir noch einmal die Definitionen für die erweiterte Überführungsfunktion und die akzeptierte Sprache jeweils für DFAs und NFAs. Bei dem DFA benutzen wir die gestrichene Variante (also \(\hat{\delta}‘\)) und passen auch ansonsten die Definition auf die Bezeichnungen in der hiesigen Konstruktion an. Wir haben dann:
Wenn man noch bedenkt, dass in der Konstruktion \(\delta'(M,x) := \cup_{z \in M} \delta (z,x)\) gesetzt wird, dann sehen die erweiterten Überführungsfunktionen fast identisch aus. Ebenso sehen die akzeptierten Sprachen fast identisch aus, wenn man die Definition von \(Z_{end}‘\) und \(z_0\) beachtet. Diese \“Ahnlichkeit ist gerade der Ursprung für die folgende Beweisidee. Statt \(L(A) = L(B)\) durch Teilmengenbeziehungen direkt zu zeigen, zeigen wir per Induktion über die Wortlänge \(|w|\), dass für jedes \(w \in \Sigma^*\) und \(M \subseteq Z\) $$ \hat\delta'(M,w) = \hat\delta(M,w) $$ gilt. Wir zeigen also, dass wir nach Lesen eines Wortes \(w\) in der gleichen Menge von Zuständen sind, also im NFA in einer Menge von Zuständen, die besagt, dass wir in diesen Zuständen nichtdeterministisch sind und im DFA in einem Zustand, der aber gerade diese gleiche Menge von Zuständen ist. (Man kann sich schon hier überlegen, dass dies dann genügt, um zu zeigen, dass beide Automaten die gleichen Worte und damit letztendlich die gleiche Sprache akzeptieren. Denn wenn diese Mengen gleich sind, dann ist in beiden entweder ein Endzustand des NFA oder eben nicht. Damit akzeptieren aufgrund der Akzeptanzbedingungen und der Konstruktion gerade beide Automaten oder eben nicht.)
Induktionsanfang: \(|w| = 0\), d.h. \(w = \lambda\). In diesem Fall ist \(\hat\delta'(M,w) = \hat\delta(M, w) = M\) (wegen der Definition der erweiterten Überführungsfunktion).
Induktionsannahme: Gelte die Induktionsbehauptung für Worte der Länge \(n \geq 0\).
Induktionsschritt: Sei nun \(w \in \Sigma^*\) mit \(|w| = n+1\). Wir zerlegen \(w\) in \(xv\) (also \(w = xv\)) mit \(x \in \Sigma\). \(x\) ist also das erste Symbol. Nach den Definitionen der erweiterten Überführungsfunktionen folgt nun
Die letztere Gleichheit folgt dabei aufgrund der Definition von \(\delta‘\) in der Konstruktion. Setzen wir zur einfacheren Notation noch \(\cup_{z \in M} \delta(z,x) =: M‘\), dann haben wir in den beiden Zeilen ganz rechts also \(\hat{\delta}(M‘, v)\) und \(\hat{\delta‘}(M‘, v)\). Nun gilt aber \(|v| = n\) und damit ist die Induktionsannahme anwendbar, d.h. es ist \(\hat{\delta}(M‘, v) = \hat{\delta}'(M‘, v)\) und damit sind oben die beiden Zeilen gleich und wir haben also \(\hat{\delta}(M, xv) = \hat{\delta‘}(M, xv)\) bzw. mit \(w = xv\) dann \(\hat{\delta}(M, w) = \hat{\delta}'(M, w)\).
Damit ist die Induktionsbehauptung gezeigt. Setzen wir zum Abschluss des Beweises nun für \(M\) die Menge \(Z_{start}\) bzw. \(z_0\) ein (was nach Konstruktion das gleiche ist), so erhalten wir
$$ \hat\delta'(z_0, w) = \hat\delta(Z_{start},w). $$
Nach Konstruktion und Definition der Akzeptanzbedingungen akzeptiert nun der NFA \(A\) genau dann, wenn \(\hat\delta(Z_{start},w) \cap Z_{end} \not= \emptyset\) und der DFA \(B\) genau dann, wenn \(\hat\delta'(z_0, w) \in Z_{end}‘\) d.h. nach Konstruktion wenn \(\hat\delta'(z_0, w) \cap Z_{end} \not= \emptyset\) gilt. Wegen \(\hat\delta'(z_0, w) = \hat\delta(Z_{start},w)\) akzeptieren also sowohl \(A\) als auch \(B\) ein Wort \(w\) oder lehnen es beide ab. Daraus folgt \(L(A) = L(B)\).
Damit haben wir gezeigt, dass wir zu jedem NFA einen DFA konstruieren können, der die gleiche Sprache akzeptiert. Da die Menge der Zustände des DFA gerade die Potenzmenge der Zustände des NFA ist, wird diese Konstruktion Potenzautomatenkonstruktion und der entstehende DFA der Potenzautomat (zu dem NFA) genannt.
Man spricht in diesem Fall von der Äquivalenz der beiden Automatenmodelle. Allgemein sagt man, dass, wenn zwei DFAs \(A_1\) und \(A_2\) die gleiche Sprache akzeptieren, wenn also \(L(A_1) = L(A_2)\) gilt, dass dann \(A_1\) und \(A_2\) äquivalent sind. Ebenso spricht man dann auch bei zwei Automaten unterschiedlicher Automatenmodelle davon, dass sie äquivalent sind, wenn sie die gleiche Sprache akzeptieren. Und letztendlich spricht man in dem Fall, dass es so wie hier möglich ist, zu jedem Automaten eines speziellen Modells einen äquivalenten Automaten eines anderen speziellen Modells zu konstruieren, davon, dass die Automatenmodelle äquivalent sind. NFAs und DFAs sind also äquivalente Automatenmodelle oder kürzer: äquivalent.
Die Familie der regulären Sprachen wird also sowohl von dem DFA als auch von dem NFA erfasst. Die Aussage eine Sprache sei regulär bedeutet also, dass es einen DFA gibt, der sie akzeptiert oder auch, dass es einen NFA gibt, der sie akzeptiert. Zusammengefasst sagen wir: Zu jeder regulären Sprache \(L\) gibt es
einen DFA \(A\) mit \(L(A) = L\) und
einen NFA \(B\) mit \(L(B) = L\).
Zum Abschluss noch der Hinweis auf den Unterschied in der Konstruktion im Beweis und im Vorgehen im Beispiel. In der Konstruktion im Beweis wurde \(Z‘ := 2^Z\) gesetzt. Im Beispiel haben wir nur die initiale Zusammenhangskomponente konstruiert. Letzteres genügt stets, d.h. man könnte die Konstruktion im Beweis so umformulieren, dass man sie algorithmisch formuliert und bei \(z_0 := Z_{start}\) beginnt und dann (so wie im Beispiel) nach und nach weitere, erreichbare Zustände (also insgesamt die initiale Zusammenhangskomponente) generiert. Der Korrektheitsbeweis geht dann ganz genauso. Die Aussagen bleiben also die gleichen, bei der Ausführung oder Implementierung ist die Variante mit der initialen Zusammenhangskomponente aber meist schneller und platzsparender. In der Konstruktion im Beweis wurde hier die eher statische Variante gewählt, um die Potenzmenge deutlich sichtbar zu machen.
Tatsächlich gibt es auch Fälle, in denen alle Zustände der Potenzmenge nötig sind, d.h. es gibt Fälle, in denen der DFA exponentiell mehr Zustände benötigt als der DFA ([/latex]2^{|Z|}[/latex] im Vergleich zu \(|Z|\)). In den meisten Fällen werden zwar nicht alle gebraucht, es gibt aber eben doch Beispiele, wo diese Zahl erreicht wird und tatsächlich auch nötig ist, d.h. die hohe Zahl ist auch keine Schwäche der Konstruktion!
Eine gute Näherung für diesen Fall hat man schon mit dem Automaten, bei dem das drittletzte Symbol ein bestimmter Buchstabe sein muss bzw. mit Verallgemeinerungen davon.
Ein äquivalenter DFA für diese Sprache hat bereits mindestens \(2^{n-1}\) Zustände.
Wir wollen noch diesen und den vorangegangenen Abschnitt zusammenfassen. Zunächst haben wir nichtdeterministische endliche Automaten (NFA) als Verallgemeinerung der DFAs eingeführt. Die hauptsächliche Änderung war, dass zu einem Zustand und einem Symbol nun mehr als ein Nachfolgezustand existieren darf. Zusätzlich wurde auch angepasst, dass der NFA auch gleich zu Beginn in mehr als einem Startzustand sein kann. Anschließend haben wir dann wo nötig die Definitionen des DFA angepasst. Wir passten also die Definition der erweiterten Überführungsfunktion an und übertrugen auch die Begriffe Konfiguration, Konfgurationsübergang, Rechnung und Erfolgsrechnung auf NFAs. Zuletzt passten wir dann die Definition der akzeptierten Sprache an.
In diesem Abschnitt haben wir dann mit der Potenzautomatenkonstruktion eine Konstruktion kennengelernt, die es uns ermöglicht zu jedem beliebigen NFA einen DFA zu konstruieren, der die gleiche Sprache akzeptiert. Die beiden Automatenmodelle sind also äquivalent und erfassen beide die Familie der regulären Sprachen. Im Beweis der Potenzautomatenkonstruktion haben wir wieder einen induktiven Beweis über die Wortlänge gesehen.
Nachdem wir also den NFA eingeführt haben, haben wir gleich gesehen, dass er gar nicht nötig ist, um wirklich neue Dinge tun zu können. Er ist aber dennoch sehr nützlich, da er es uns erlaubt in vielen Fällen eine viel kompaktere Darstellung für eine reguläre Sprache zu haben, als dies mit DFAs möglich ist. Zudem führten wir mit ihm das Konzept des Nichtdeterminismus ein, das uns später noch oft begegnen wird und sich als sehr nützlich erweisen wird.
Zeitlimit: 0
Quiz-Zusammenfassung
0 von 8 Fragen beantwortet
Fragen:
1
2
3
4
5
6
7
8
Informationen
Hier ein paar Fragen zum Vergleich von DFAs und NFAs.
Sie haben das Quiz schon einmal absolviert. Daher können sie es nicht erneut starten.
Quiz wird geladen...
Sie müssen sich einloggen oder registrieren um das Quiz zu starten.
Sie müssen erst folgende Quiz beenden um dieses Quiz starten zu können:
Ergebnis
0 von 8 Frage korrekt beantwortet
Ihre Zeit:
Zeit ist abgelaufen
Sie haben 0 von 0 Punkten erreicht (0)
Kategorien
Nicht kategorisiert0%
1
2
3
4
5
6
7
8
Beantwortet
Vorgemerkt
Frage 1 von 8
1. Frage
Kann zu jedem NFA mittels der Potenzautomatenkonstruktion ein DFA konstruiert werden oder gibt es Ausnahmen?
Korrekt
Inkorrekt
Frage 2 von 8
2. Frage
Wie ist der Startzustand des DFA in der Potenzautomatenkonstruktion definiert?
Korrekt
Inkorrekt
Frage 3 von 8
3. Frage
Wie ist die Endzustandsmenge des DFA in der Potenzautomatenkonstruktion definiert?
Korrekt
Inkorrekt
Frage 4 von 8
4. Frage
Welche Aussage stimmt für einen Potenzautomaten, der wie im Beweis angegeben konstruiert wurde?
Korrekt
Inkorrekt
Frage 5 von 8
5. Frage
Welche Aussage stimmt für einen Potenzautomaten, der wie im Beispiel beschrieben konstruiert wurde?
Korrekt
Inkorrekt
Frage 6 von 8
6. Frage
Sie \(A\) ein deterministischer endlicher Automat. Was ist richtig?
Korrekt
Inkorrekt
Frage 7 von 8
7. Frage
Sie \(A\) ein nichtdeterministischer endlicher Automat. Was ist richtig?
Korrekt
Inkorrekt
Frage 8 von 8
8. Frage
Können Sie zu dem zuletzt in diesem Abschnitt angegebenen NFA einen DFA mit der Potenzautomatenkonstruktion bauen?
Bei einem vollständigen DFA gibt es zu jedem Zustand \(z\), in dem sich der DFA befindet, und jedem Eingabesymbol \(x\), das er in diesem Zustand liest, genau einen Nachfolgezustand \(\delta(z,x) = z‘\). Ist der DFA nicht vollständig, dann gibt es höchstens einen Nachfolgezustand. Man spricht daher davon, dass der Nachfolgezustand beim DFA determiniert ist (darum auch die Bezeichnung als deterministischer endlicher Automat). Ist ein DFA \(A\) nämlich in einem Zustand \(z\), dann gibt es stets nur genau eine Möglichkeit, was bei einem Symbol \(x\) passiert. Entweder passiert der Zustandswechsel zu einem ganz bestimmten Zustand oder der Automat blockiert.
In den späten 1950er Jahren kam die Idee auf, der Übergangsfunktion des DFA mehr Freiheiten einzuräumen. Statt nur einen Nachfolgezustand zu haben, darf der neue Automat nun beim Lesen eines Buchstaben mehrere Nachfolgezustände haben.
Im abgebildeten Automaten gibt es in \(z_0\) zwei Möglichkeiten den Zustand beim Lesen von \(a\) zu wechseln. Die Idee ist, dass nichtdeterministisch ein Nachfolgezustand gewählt wird. Man interpretiert dies so, dass der Automat sowohl in \(z_1\) als auch in \(z_2\) ist und quasi in der Rückschau das bessere ausgewählt wird.
Akzeptiert wird daher, informal ausgedrückt, sobald es mindestens eine Rechnung gibt, die den Automaten vom Start- in einen Endzustand bringt. Endliche Automaten, die wie der abgebildete Automaten mehrere gleichbeschriftete Kanten aus einem Zustand heraus haben, also nichtdeterministisch sind, werden als NFA (nichtdeterministischer endlicher Automat) bezeichnet.
Nichtdeterminismus einzuführen war eine wegweisende Idee, die uns an vielen Stellen in der Informatik begegnet. Hier ist sie insb. deswegen nützlich, weil sie uns oft erlaubt, auf einfache Weise Automaten zu entwerfen, die als DFAs viel komplizierter sind. Will man z.B. einen Automaten für alle Worte, die auf \(1\) enden, so kann man dafür schnell den neben stehend abgebildeten Automaten konstruieren.
Der DFA ist in diesem Fall nicht viel komplexer, aber man versuche dies einmal zu verallgemeinern und z.B. einen DFA zu entwerfen, der jene Worte akzeptiert, dessen fünftletzter Buchstabe \(1\) ist. Dies ist ein recht großer und schwer zu lesender DFA, mit Nichtdeterminismus aber sehr schnell konstruiert.
Zudem werden wir Nichtdeterminismus bei späteren Automatenmodellen benötigen und insb. bei der Turingmaschine und der damit zusammenhängenden Komplexitätstheorie wird dieses Konzept unglaublich hilfreich sein. Mit ihm lassen sich einige der ganz großen offenen Fragen der Informatik formulieren.
Definition des NFA
Den nichtdeterministischen endlichen Automaten (kurz: NFA) können wir formal fast wie den DFA einführen. Wir müssen nur bei der Übergangsfunktion etwas anders machen, um mehrere Nachfolgezustände ausdrücken zu können. Dies gelingt indem wir die Zielmenge von \(Z\) zu \(2^Z\) ändern. Damit ist \(\delta(z,x)\) dann eine Menge von Zuständen. In dieser Menge sind dann gerade jene Zustände, die von \(z\) aus mit \(x\) erreichbar sind.
Zusätzlich wollen wir auch eine Menge von Startzuständen zulassen. Dies beschreibt, dass wir auch nach dem Lesen von null Symbolen nichtdeterministisch in mehreren Zuständen sein können, das also bereits der Anfang nichtdeterminiert ist.
Formal können wir dies nun wie folgt exakt ausdrücken.
Ein nichtdeterministischer, endlicher Automat (NFA) ist ein \(5\)-Tupel
$$ A = (Z, \Sigma, \delta, Z_{start}, Z_{end}) $$ mit:
Der endlichen Menge von Zuständen \(Z\).
Dem endlichen Alphabet \(\Sigma\) von Eingabesymbolen.
Der Überführungsfunktion \(\delta: Z \times \Sigma \rightarrow 2^Z\).
Der Startzustandsmenge \(Z_{start} \subseteq Z\).
Der Menge der Endzustände \(Z_{end} \subseteq Z\).
Die graphische Darstellung ist wie beim DFA.
Alternativ kann statt der Überführungsfunktion \(\delta\) auch mit der Zustandsübergangsrelation $$ K \subseteq Z \times \Sigma \times Z $$ arbeiten. Ein Tupel \((z,x,z‘)\) drückt dann aus, das es von \(z\) eine Kante nach \(z‘\) gibt, die mit \(x\) beschriftet ist. Es ist dann bei einem NFA möglich weitere Kanten mit gleichem Ursprung und gleichem Symbol zu haben, also z.B. zwei Kanten \((z,x,z‘)\) und \((z,x,z“)\).
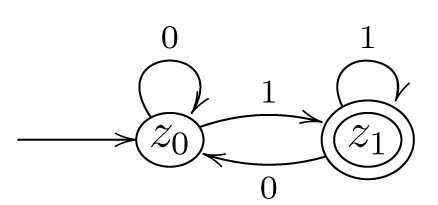
Im abgebildeten Automaten ist dann \(Z = \{z_0, z_1\}\), \(\Sigma = \{0,1\}\) und \(Z_{end} = \{z_1\}\) wie beim DFA. Da dies ein NFA ist, haben wir aber, obwohl es in diesem Fall wie beim DFA nur ein Startzustand ist, eine Startzustandsmenge, also ist \(Z_{start} = \{z_0\}\).
Die Überführungsfunktion ist durch \(\delta(z_0, 0) = \{z_0\}\) und \(\delta(z_0, 1) = \{z_0, z_1\}\) gegeben. Außerdem kann man \(\delta(z_1, 0) = \delta(z_1, 1) = \emptyset\) setzen.
Als Zustandsübergangsrelation ist \(K\) gegeben durch \(K = \{(z_0,0,z_0), (z_0,1,z_0), (z_0,1,z_1)\}\).
Da wir die Überführungsfunktion angepasst haben, müssen wir auch die erweiterte Überführungsfunktion und letztendlich die akzeptierte Sprache anpassen. Für die erweiterte Überführungsfunktion definieren wir folgendes.
Sei \(A = (Z, \Sigma, \delta, Z_{start}, Z_{end})\) ein NFA. Die erweiterte Überführungsfunktion \(\hat{\delta}: 2^Z \times \Sigma^* \rightarrow 2^Z\) wird für alle \(Z‘ \subseteq Z\), \(x \in \Sigma\) und \(w \in \Sigma^*\) rekursiv definiert durch
Wir werden meistens mit der zweiten Alternative arbeiten. Hier sammeln sich die nichtdeterministisch erreichten Zustände in der Menge im ersten Argument.
Man beachte, wie sich im ersten Argument die Menge der erreichten Zustände sammelt. Um z.B. \(\hat{\delta}(\{z_0, z_1\}, ba) = \hat{\delta}(\{z_0\} \cup \{z_2\}, a)\) zu sehen, muss man die Nachfolgezustände von \(\{z_0, z_1\}\) beim Lesen des nächsten Buchstabens (also von \(b\)) ermitteln. Dazu nimmt man die Menge der Zustände, die von \(z_0\) aus durch \(b\) erreicht werden (also \(\delta(z_0, b) = \{z_0\}\)) und vereinigt diese mit der Menge der Zustande, die von \(z_1\) durch \(b\) aus erreichbar sind (also mit \(\delta(z_1, b) = \{z_2\}\)). Damit ergibt sich obiges.
Bevor wir zur akzeptierten Sprache kommen, können wir noch wie beim DFA die Konfiguration, Konfigurationsübergänge, sowie Rechnungen und Erfolgsrechnungen definieren.
Definition 2.2.3 (Konfiguration und Rechnung)
Eine Konfiguration eines NFA \(A\) ist ein Tupel \((z,w) \in Z \times \Sigma^*\)
mit der Bedeutung, dass \(A\) im Zustand \(z\) ist und noch das Wort \(w\) zu lesen ist.
Ein Konfigurationsübergang ist dann
$$ (z,w) \vdash (z‘,v) $$
genau dann, wenn \(w = xv\), \(x \in \Sigma\) und \(z‘ \in \delta(z,x)\) ist.
Eine Rechnung auf dem Wort \(w \in \Sigma^*\) ist eine Folge von Konfigurationsübergängen,
die in \((z_0, w)\) mit \(z_0 \in Z_{start}\) beginnt.
Endet eine Rechnung in \((z‘, \lambda)\) und ist \(z‘ \in Z_{end}\),
so ist dies eine Erfolgsrechnung.
Man beachte wie gering die Unterschiede zum DFA sind. Beim DFA wird beim Konfigurationsübergang \(z‘ = \delta(z,x)\) gefordert, hier wird \(z‘ \in \delta(z,x)\) gefordert. Bei der Rechnung wird gefordert, dass \(z_0\) ein Startzustand ist (wie beim DFA auch, aber hier könnte man mehrere zur Auswahl haben).
Man beachte insbesondere aber auch, dass anders als beim DFA hier bei der Konfiguration Informationen verloren gehen! Ein NFA kann sozusagen in mehreren Konfigurationen gleichzeitig sein. Der Sinn hier ist, dass man über bestimmte Rechnungen ähnlich wie beim DFA sprechen will.
Wir können nun die akzeptierte Sprache definieren.
Definition 2.2.4 (Akzeptierte Sprache)
Die von einem NFA \(A\) akzeptierte Sprache} ist die Menge
\( \begin{eqnarray*}
L(A) & := & \{w \in \Sigma^* \mid \hat{\delta}(Z_{start}, w) \cap Z_{end} \not= \emptyset \} \\
& = & \{w \in \Sigma^* \mid (z_0, w) \vdash^* (z_e, \lambda), z_0 \in Z_{start}, z_e \in Z_{end}\}
\end{eqnarray*}\)
Ein NFA \(A\) akzeptiert also ein Eingabewort \(w\) dann, wenn auf \(w\) eine Erfolgsrechnung existiert, d.h. wenn es eine Rechnung gibt, die in \((z_0, w)\) mit \(z_0 \in Z_{start}\) beginnt und in \((z_e, \lambda)\) mit \(z_e \in Z_{end}\) endet. Die Notation \(\hat{\delta}(Z_{start}, w) \cap Z_{end} \not= \emptyset\) drückt das gleiche aus, nutzt aber die erweiterte Überführungsfunktion.
Im ersten Fall blockiert der Automat, da es in \(z_1\) keine \(1\)-Kante gibt. Im zweiten Fall lehnt der Automat das Wort ab, da die Rechnung in \(z_0\) endet und dies kein Endzustand ist.
Im dritten Fall ist das Wort zu Ende gelesen und der Automat in einem Endzustand, also wird das Wort akzeptiert. Wegen dieses dritten Falles wird das Wort auch ganz allgemein akzeptiert, soll heißen: es gilt \(001 \in L(A)\).
Man mache sich noch einmal klar, dass ein NFA ein Wort akzeptiert, sobald es irgendeine Rechnung gibt, die ihn von einem Start- zu einem Endzustand bringt. Ein NFA muss, um ein Wort zu akzeptieren, dieses wie ein DFA zu Ende gelesen haben und er muss dann in einem Endzustand sein. Er kann aber auf einem Wort mehrere Rechnungen haben und es genügt, wenn mindestens eine davon eine Erfolgsrechnung ist.
Zeitlimit: 0
Quiz-Zusammenfassung
0 von 4 Fragen beantwortet
Fragen:
1
2
3
4
Informationen
Hier ein paar Fragen zu NFAs.
Sie haben das Quiz schon einmal absolviert. Daher können sie es nicht erneut starten.
Quiz wird geladen...
Sie müssen sich einloggen oder registrieren um das Quiz zu starten.
Sie müssen erst folgende Quiz beenden um dieses Quiz starten zu können:
Ergebnis
0 von 4 Frage korrekt beantwortet
Ihre Zeit:
Zeit ist abgelaufen
Sie haben 0 von 0 Punkten erreicht (0)
Kategorien
Nicht kategorisiert0%
1
2
3
4
Beantwortet
Vorgemerkt
Frage 1 von 4
1. Frage
Sei folgender NFA gegeben. Was ist \(\hat{\delta}(\{z_0\}, aaa)\)?
Korrekt
Inkorrekt
Frage 2 von 4
2. Frage
Sei folgender NFA gegeben. Was ist \(\hat{\delta}(\{z_0\}, aba)\)?
Korrekt
Inkorrekt
Frage 3 von 4
3. Frage
Sei folgender NFA gegeben. Gibt es eine Rechnung auf \(aaa\), bei der \(A\) blockiert?
Korrekt
Inkorrekt
Frage 4 von 4
4. Frage
Sei folgender NFA gegeben. Welche Sprache akzeptiert dieser NFA?
Üblicherweise ist eine Sprache \(M\) gegeben oder wir interessieren uns für eine Menge von Worten \(M\), die wir selbst spezifizieren. Dies könnte z.B. die Menge aller Worte sein, die auf \(0\) enden oder ähnliches. Die Frage ist dann, wie wir zu dieser Sprache \(M\) einen DFA konstruieren können, der \(M\) akzeptiert (und später auch ob überhaupt).
Der andere Fall, dass wir einen Automaten \(A\) haben und uns für seine akzeptierte Sprache interessieren, tritt viel seltener und überwiegend nur zu didaktischen Zwecken auf. Dieser Fall ist vergleichbar damit, dass man unkommentierten Programmcode erhält und dessen Bedeutung herausfinden muss.
Wie gehen wir nun vor, wenn wir eine Sprache \(M\) haben und einen Automaten \(A\) mit \(L(A) = M\) konstruieren wollen? Dieser Entwurf eines Automaten erfordert von uns Kreativität und lässt sich nicht automatisieren, d.h. es gibt kein Rezept dafür, dem wir folgen können, um am Ende den Automaten \(A\) zu haben. Es gibt allerdings Techniken, die man erlernen kann und je nach \(M\) vielleicht anwenden kann. Wir wollen nachfolgend zwei solcher Techniken erläutern und jeweils anhand eines Beispiels illustrieren.
Technik 1: Mit dem Speicher arbeiten
Bei der ersten Technik fragen wir uns, was für Informationen wir speichern wollen und wie wir dies mit den Zuständen machen können. Der endliche Automat hat ja eine endliche Menge von Zuständen und diese endliche Menge kann genutzt werden, um endliche viele Informationen zu speichern. Z.B. könnte man sich für das zuletzt gelesene Symbol der Menge \(\Sigma = \{0,1\}\) interessieren und dafür zwei Zustände \(z_0\) und \(z_1\) anlegen. In \(z_0\) wechselt man dann, wenn man eine \(0\) liest, in \(z_1\), wenn man eine \(1\) liest. Im Index des Zustands merkt man sich also das zu letzt gelesene Symbol. Wichtig hierbei ist, dass man sich nur endlich viele Informationen merken kann. Man muss also aus der gegebenen Sprache \(M\) wichtige Eigenschaften herleiten, die man in den Zuständen speichert und die einem dann tatsächlich bei der Akzeptierung der Worte aus \(M\) nützen. Ferner muss es auch möglich sein, die Informationen zu aktualisieren. Oben geschah dies ganz einfach stets beim Lesen des nächsten Symbols.
Wir wollen diese Technik an einem Beispiel verdeutlichen. Sei
$$ M := \{ w \in \{0,1\}^* \mid \text{ \(|w|_0\) ist gerade und \(|w|_1\) ist ungerade} \} $$ In \(M\) sind also jene Worte aus \(0\)en und \(1\)en, die eine gerade Anzahl an \(0\)en und eine ungerade Anzahl an \(1\) en enthalten. Zum Beispiel ist also \(01110 \in M\) (zwei \(0\)en und drei \(1\)en), nicht aber \(0101\) (die Anzahl der \(0\)en ist zwar gerade, die der \(1\)en aber auch).
Wie konstruieren wir hierzu nun einen DFA? Dazu muss man sich überlegen, welche speziellen Eigenschaften ein Wort aus \(M\) hat und ob man sich diese Eigenschaften mit endliche vielen Informationen merken kann. Bevor unten ein Lösungsvorschlag kommt, kann man an dieser Stelle einmal selbst ausprobieren, ob man auf eine Lösung kommt.
Ein Wort \(w \in M\) hat die Eigenschaft gerade viele \(0\)en und ungerade viele \(1\)en zu enthalten. Wenn wir nun die Anzahl der \(0\)en und der \(1\)en zählen und diese Information im Zustand speichern wollen, dann brauchen wir unendlich viele Zustände, da wir ja Hundert oder auch Tausend oder auch Zehntausend \(0\)en lesen können. Dieser Ansatz geht also nicht. Wir brauchen aber auch gar nicht die genaue Anzahl der \(0\)en und \(1\)en. Es genügt ja zu wissen, ob wir bis zu einem bestimmten Zeitpunkt gerade oder ungerade viele \(0\)en gesehen haben. Dies sind zwei Informationen (gerade oder ungerade) für zwei Symbole ([/latex]0[/latex] und \(1\)), also brauchen wir insgesamt nur vier Zustände für die vier Fälle gerade viele \(0\)en und gerade viele \(1\)en, gerade viele \(0\)en und ungerade viele \(1\)en usw. Zudem können wir die gespeicherten Informationen leicht aktualisieren, wenn der Automat eine \(0\) oder eine \(1\) liest.
Um dies im Detail auszuführen nehmen wir als Zustände \(z_{gg}, z_{ug}, z_{gu}\) und \(z_{uu}\). Ein \(u\) im Index steht dabei für ungerade, ein \(g\) für gerade. Das erste Symbol steht für die \(0\)en, das zweite für die \(1\)en. Der Zustand \(z_{ug}\) soll also erreicht werden, wenn wir ungerade viele \(0\)en und gerade viele \(1\)en gelesen haben. Als Startzustand macht dann \(z_{gg}\) Sinn, da wir null gelesene \(0\)en und null gelesene \(1\)en als gerade viele \(0\)en und \(1\)en ansehen wollen. Der Endzustand ist mit Blick auf die Menge \(M\) dann \(z_{gu}\). Damit haben wir als Zustandsübergangsdiagramm des Automaten \(A\) bisher den gezeigten Automaten.
Wenn wir nun in \(z_{gg}\) sind und eine \(0\) lesen, dann ändert sich die gespeicherte Information, dass wir gerade viele \(0\)en gelesen haben, denn es kommt ja eine dazu und damit sind es nun ungerade viele. Die gespeicherte Information zu den \(1\)en hingegen ändert sich nicht. Wir machen also eine \(0\)-Kante in den Zustand \(z_{ug}\), da wir nun ungerade viele \(0\)en und weiterhin gerade viele \(1\)en gelesen haben.
Ebenso machen wir eine \(1\)-Kante von \(z_{gg}\) nach \(z_{gu}\). Dies ergibt als Automat nun folgendes Bild.
Man überlegt sich dann schnell, dass für die eben eingezeichneten Kanten auch Kanten mit der gleichen Beschriftung zurück nötig sind, da gerade wieder die gleiche gespeicherte Information geändert werden muss. Ebenso kann man sich für die verbleibenden Zustände und Symbole die Kanten überlegen. Ist man z.B. in \(z_{uu}\), so hat man ungerade viele \(0\)en und \(1\)en gelesen und ein Lesen von \(0\) führt dann in \(z_{gu}\), da man dann gerade viele \(0\)en und weiterhin ungerade viele \(1\)en gelesen hat. Insgesamt ergibt sich damit der abgebildete Automat.
Wir sind mit der Konstruktion fertig, da wir einen Startzustand haben, eine Endzustandmenge und für jedes Symbol Kanten aus jedem Zustand heraus (der Automat ist also sogar vollständig). Es ist nun aber wie im vorherigen Abschnitt zunächst nur eine Behauptung, dass \(L(A) = M\) tatsächlich gilt. Dies ist nun noch zu beweisen! Dazu kann man sich zuerst überlegen, dass für jeden Zustand und alle Kanten gilt, dass die Informationen richtig neu gesetzt werden. Wenn man also in einem Zustand \(z_{xy}\) ist und mit einer \(0\)-Kante den Zustand \(z_{x'y}\) erreicht bzw. mit einer \(1\)-Kante den Zustand \(z_{xy'}\), dann wird \(x\) richtig in \(x'\) bzw. \(y\) richtig in \(y'\) geändert. Exemplarisch haben wir das bereits oben für einige argumentiert. Man kann am Zustandsdiagramm sehen, dass dies tatsächlich für alle Zustände und alle Kanten gilt. Dies erlaubt gleich die Formulierung, dass bestimmte Dinge "nach Konstruktion" gelten. Wir zeigen nun \(L(A) = M\).
Sei \(w \in M\), dann kann \(w\) nach Konstruktion (der Automat ist vollständig) zu Ende gelesen werden. Nach Konstruktion der Zustände und der Zustandsübergänge (s.o.) enden wir dann in \(z_{gu}\) (da \(w\) eine gerade Anzahl von \(0\)en und eine ungerade Anzahl von \(1\)en enthält) und akzeptieren. Also ist auch \(w \in L(A)\).
Sei \(w \in L(A)\). Da \(w\) akzeptiert wird, muss \(A\) in \(z_{gu}\) enden. Dies ist aber nach Konstruktion (s.o.) gleichbedeutend damit, dass \(w\) gerade viele \(0\)en und ungerade viele \(1\)en enthält. Damit gilt auch \(w \in M\).
Die Formulierung "nach Konstruktion" macht hier Sinn, da wir oben die Idee sauber beschrieben haben und für alle Zustände und Kanten erklären können was passiert. Zudem ist der Automat hinreichend klein und übersichtlich, so dass man dies hier so akzeptieren kann. Noch sauberer gelingt der Beweis mit einer vollständigen Induktion über die Wortlänge. Hier wird dann ebenfalls oben ausgeführtes zu den Zuständen und den Zustandsübergängen benutzt. Man kann aber besser argumentieren, warum man z.B. bei der ersten Beweisrichtung tatsächlich in \(z_{gu}\) landet. Diese Stelle wäre oben noch angreifbar.
Wir beweisen \(L(A) = M\) noch einmal mit Induktion über die Wortlänge. Das schwierige ist dann insb. eine gute Induktionsbehauptung aufzustellen.
Sei \(w = w_1 \ldots w_n \in \{0,1\}^*\) (mit \(w_1, \ldots, w_n \in \{0,1\}\)). Wir zeigen mittels Induktion über die Wortlänge \(n\): \(w\) kann von \(A\) gelesen werden und \(A\) endet in \(z_{gg}\), wenn \(|w|_0\) und \(|w|_1\) gerade sind, in \(z_{gu}\), wenn \(|w|_0\) gerade und \(|w|_1\) ungerade ist, in \(z_{ug}\), wenn \(|w|_0\) ungerade und \(|w|_1\) gerade ist und in \(z_{uu}\), wenn \(|w|_0\) und \(|w|_1\) ungerade sind.
Induktionsanfang: Sei \(n = 0\), dann ist \(w = \lambda\), \(|w|_0\) und \(|w|_1\) sind gerade und \(A\) kann \(w\) lesen und endet in \(z_{gg}\) wie gewünscht.
Induktionsannahme: Die Induktionsbehauptung gelte für ein \(n \geq 0\)
.
Induktionsschritt: Sei nun \(w = w_1 \ldots w_n w_{n+1}\) ein Wort der Länge \(n+1\). Wir wenden auf \(w' := w_1 \ldots w_n\) die Induktionsannahme an. \(A\) kann \(w'\) also lesen und endet in einem seiner vier Zustände, je nachdem, ob \(|w'|_0\) und \(|w'|_1\) gerade oder ungerade sind. Wir machen eine Fallunterscheidung. Angenommen \(w'\) hat eine gerade Anzahl von \(0\)en und \(1\)en und angenommen \(w_{n+1}\) ist eine \(0\), dann ist \(|w|_0\) ungerade ([/latex]|w'|_0[/latex] haben wir als gerade angenommen und \(w_{n+1}\) als \(0\), damit ist \(|w|_0\) ungerade) und \(|w|_1\) gerade.
Wir müssen nun zeigen, dass \(w\) von \(A\) gelesen werden kann und dass \(A\) nach Lesen von \(w\) in \(z_{ug}\) ist. Nach der Induktionsannahme und da \(|w'|_0\) und \(|w'|_1\) gerade sind, kann \(A\) das Teilwort \(w'\) lesen und ist nach Lesen von \(w'\) in \(z_{gg}\). Nach Konstruktion überführt \(w_{n+1} = 0\) dann \(A\) nach \(z_{ug}\). Damit haben wir das Gewünschte für diesen Fall bereits gezeigt.
Analog behandelt man den Fall, dass \(w_{n+1}\) eine \(1\) ist und dann ganz analog die Fälle, dass \(A\) nach Lesen von \(w'\) in einem der anderen drei Zustände ist. Insgesamt sind hier also acht Fälle zu behandeln (die vier Zustände, in denen \(A\) nach Lesen von \(w'\) ist sowie dann jeweils \(w_{n+1} = 0\) oder \(w_{n+1} = 1\)).
Damit haben wir die Induktionsbehauptung gezeigt. Sei nun \(w \in M \subseteq \{0,1\}^*\). Dann wissen wir, dass \(|w|_0\) gerade und \(|w|_1\) ungerade ist. Nach dem eben bewiesen überführt uns \(w\) also in \(z_{gu}\) und da dies ein Endzustand ist, gilt \(w \in L(A)\).
Dies sieht alles sehr ähnlich zu obigem aus. Die Konstruktionsidee findet sich im Induktionsschritt wieder. Insgesamt ist der Beweis so aber sauberer als der oben zuerst geführte. In diesem kleinen Beispiel hätte der oben zuerst geführte aber auch genügt. Der Leser muss sich dann aber an der Stelle "Nach Konstruktion der Zustände und der Zustandsübergänge (s.o.) enden wir dann in \(z_{gu}\)"selbst davon überzeugen können, dass die Aussage stimmt. Das ist bei diesem kleinen Beispiel noch recht eingängig. Mit einer Induktion aber stichhaltiger gezeigt.
Sei \(w \in L(A)\). Wir wollen \(w \in M\) zeigen. Betrachten wir noch einmal obige Induktionsbehauptung, dann haben wir dort wenn-dann-Formulierungen der Art \emph{wenn \(|w|_0\) und \(|w|_1\) gerade sind, dann endet \(A\) in \(z_{gg}\)}. Da es bezüglich gerader und ungerader Anzahl der \(0\)en und \(1\)en nur die vier Fälle für Worte \(w \in \{0,1\}^*\) gibt, sind dies sogar genau-dann-wenn-Beziehungen, d.h. wir können aus obigen sofort auch schlussfolgern, dass z.B. \(|w|_0\) und \(|w|_1\) gerade sind, wenn \(A\) in \(z_{gg}\) endet. (Angenommen \(|w|_0\) und \(|w|_1\) wären nicht beide gerade, dann würde aus der oben bewiesene Induktionsbehauptung folgen, dass \(A\) nicht in \(z_{gg}\), sondern in einem der anderen Zustände endet. Wir sind ja aber gerade davon ausgegangen, dass wir in \(z_{gg}\) enden und hätten hier einen Widerspruch.) Mit dieser Überlegung folgt der Beweis nun ganz schnell. Sei \(w \in L(A)\), dann enden wir in \(z_{gu}\), da dies der einzige Endzustand ist. Dann aber folgt aus dem eben beschriebenen sofort, dass \(|w|_0\) gerade und \(|w|_1\) ungerade ist und damit \(w \in M\) gilt. (Diese Richtung erscheint deswegen so kurz, weil wir im Grunde genommen oben bei der Induktionsbehauptung auch "genau dann, wenn"-Beziehungen gezeigt haben und daher die dortige Aussage hier benutzen können.)
Damit sind wir mit diesem Beispiel fertig.
Wir wollen noch anmerken, dass bei dieser Technik bisweilen ein Teil konstruiert wird, der dann gar nicht benötigt wird. Dies kann passieren, wenn man zunächst Speicherinhalte berücksichtig, von denen man später bemerkt, dass man sie gar nicht braucht, weil sie (doch) nicht entstehen können. Dies ist aber nicht weiter tragisch, man würde sich dann einfach im Nachhinein auf die initiale Zusammenhangskomponente (also jenen Teil des Automaten, der vom Startzustand aus erreichbar ist) einschränken.
Technik 2: On-the-fly-Entwurf
Die zweite Technik, die wir kennenlernen wollen ist eine „on-the-fly“-Technik. Man fängt hier mit dem Startzustand an und überlegt sich dann für jedes Eingabesymbol \(x \in \Sigma\), ob einem dieses weitere Informationen bringt, die man speichern will oder nicht. Der so entstehende Automat ist stets initial zusammenhängend und vollständig. Man muss bei der Konstruktion aber darauf achten, dass man irgendwann zu Zuständen zurück kommt, die man bereits generiert hatte, sonst generiert man unendlich viele Zustände.
Wir wollen diese Technik wieder an einem kleinen Beispiel demonstrieren. Sei $$M := \{0,1\}^* \{1\} = \{w \in \Sigma^* \mid \exists v \in \Sigma^*: w = v1\}$$ In \(M\) sind also jene Worte aus \(0\)en und \(1\)en, die auf \(1\) enden. Beispielsweise ist \(0101\) (letztes Symbol ist \(1\)) enthalten, nicht aber \(1010\) (letztes Symbol ist \(0\), nicht \(1\)).
Wir könnten mit der ersten Konstruktionsmethode hierzu einen Automaten bauen, indem wir uns im Speicher merken, was das zuletzt gelesene Symbol ist. Dazu brauchen wir nur zwei Zustände, den das zuletzt gelesene Symbol ist entweder \(0\) oder \(1\). Wir wollen aber nachfolgend die On-the-fly-Technik illustrieren. Man kann trotzdem einmal probieren zunächst selbst einen Automaten zu bauen und seine Richtigkeit zu beweisen, bevor man weiter liest.
Wir starten mit einem Startzustand (denn jeder DFA hat einen Startzustand) und fragen uns nun für jedes Symbol aus \(\Sigma\), was wir mit diesem Symbol anstellen können.
Bei einer \(0\) wissen wir nicht, ob das letzte Symbol eine \(1\) ist (vielleicht haben wir sogar gerade das letzte Symbol gelesen). Auf jeden Fall wollen wir also nicht akzeptieren. Wir könnten nun einen neuen Zustand erstellen und eine \(0\)-Kante dorthin machen. Bei genauerer Betrachtung merkt man aber, dass dieser Zustand im Vergleich zu \(z_0\) keinen Mehrwert hat. Wir wissen im Grunde genauso viel wie vorher. Daher machen wir besser eine \(0\)-Schleife an \(z_0\).
Bei einer \(1\) hingegen müssen wir den Zustand wechseln. Dies könnte ja das letzte Symbol des Wortes sein und dann wollen wir akzeptieren. Wir machen uns also einen neuen Zustand und lassen dort eine \(1\)-Kante von \(z_0\) hinführen. Dies muss zudem ein Endzustand sein, denn diese \(1\) könnte ja das letzte Symbol des Wortes sein und dann wollen wir akzeptieren.
Mit dem Zustand \(z_0\) sind wir nun fertig, denn wir haben für jedes Symbol eine Kante. Wir haben allerdings einen neuen Zustand \(z_1\) erzeugt und müssen uns nun fragen, was hier für die einzelnen Symbole von \(\Sigma\) passiert.
Wenn wir in \(z_1\) sind und eine \(1\) lesen, dann ist weiterhin das letzte gelesene Symbol eine \(1\) und wenn dies sogar das letzte Symbol des Wortes ist, wollen wir akzeptieren. Wir verbleiben also in \(z_1\). Wichtig hier ist wieder zu erkennen, dass es nicht nötig ist, einen neuen Zustand einzuführen, sondern dass wir auch nach Lesen weiterer \(1\)en in \(z_1\) verbleiben können, da wir hier genau die Informationen haben, die wir brauchen.
Lesen wir aber hingegen eine \(0\), so müssen wir \(z_1\) verlassen, denn nun ist das letzte gelesene Symbol keine \(1\) mehr und wenn das Wort mit dieser \(0\) endet, dann wollen wir ganz bestimmt nicht akzeptieren. Wir könnten nun einen neuen Zustand \(z_2\) machen und dort die \(0\)-Kante von \(z_1\) hinführen. Dann hätten wir einen weiteren Zustand und müssten uns wieder fragen, was hier bei einer \(0\) oder bei einer \(1\) passiert. Bemerkt man aber an dieser Stelle, dass man wieder die gleichen Informationen hat wie in \(z_0\), so kann man dorthin wechseln und spart sich dies. Der Automat ist dann fertig, da man für alle Zustände Kanten für alle Symbole hat. Der Automat ist also vollständig.
Wie immer muss nun aber noch \(L(A) = M\) bewiesen werden. Dies geht allerdings hier deutlich einfacher als in dem vorherigen Beispiel. Man beachte, dass der Automat vollständig ist (also jedes Wort \(w \in \{0,1\}^*\) lesen kann) und dass jede \(1\)-Kante nach \(z_1\) führt.
Sei \(w = v1 \in M\) mit \(v \in \{0,1\}^*\). Da der Automat vollständig ist, können \(v\) und \(w\) auf jeden Fall ganz gelesen werden. Da \(w\) auf \(1\) endet, muss der Automat mit dieser letzten \(1\) nach Konstruktion (jeder Zustand hat eine \(1\)-Kante nach \(z_1\)) in den Zustand \(z_1\) wechseln – oder anders: egal wo wir nach Lesen von \(v\) sind, die folgende \(1\) führt uns nach \(z_1\). Mit \(z_1 \in Z_{end}\) folgt \(w \in L(A)\).
Sei \(w \in L(A)\). Dann muss nach Konstruktion das Wort auf \(1\) enden, da \(z_1\) der einzige Endzustand ist und alle Kanten nach \(z_1\) mit \(1\) beschriftet sind. Dann ist aber sofort auch \(w \in M\).
Damit sind wir auch mit diesem Beispiel fertig.
Wir betonen noch einmal, dass es bei dieser Konstruktionsmethode kritisch ist irgendwann zu merken, wann bereits vorhandene Zustände benutzt werden können – und im besten Fall auch, wofür sie stehen; bspw. kann man oben \(z_x\) mit „letztes gelesenes Symbol ist \(x\)“ identifizieren (\(x \in \{0,1\}\)). Ansonsten konstruiert man immer weiter Zustände und der Automat wird nicht endlich.
Ein kompliziertes Beispiel
Wir wollen zum Abschluss dieses Abschnittes noch ein komplizierteres Beispiel betrachten. Bei einigen der oben bisher betrachteten Mengen und Automaten mag der ein oder andere denken, dass man die Lösung doch gleich sehe und warum man dann so umständlich argumentieren müsse? Die bisherigen Beispiele sollten das Vorgehen einüben und waren deswegen nicht zu kompliziert gewählt, damit man nicht sofort von umständlichen Argumentationen überwältigt wird. So konnte man sich auf das Vorgehen an sich konzentrieren und die Argumentationen blieben vergleichsweise übersichtlich. Damit wir aber noch einmal sehen können, dass die Argumente durchaus komplexer werden können, betrachten wir nun noch ein komplizierteres Beispiel.
Sei zunächst $$ \Sigma = \{ \begin{bmatrix} x \\ y \\ z \end{bmatrix} \mid x,y,z \in \{0,1\} \}. $$ Ein Symbol aus \(\Sigma\) ist also eine Art Vektor mit drei Elementen oder für uns nachfolgend besser mit drei Zeilen. Ein Wort aus \(\Sigma^*\) kann dann nämlich als drei Zeilen mit \(0\)en und \(1\)en gesehen werden. Im Wort
$$ \begin{bmatrix} 0 \\ 0 \\ 1 \end{bmatrix}
\begin{bmatrix} 1 \\ 1 \\ 1 \end{bmatrix}
\begin{bmatrix} 1 \\ 1 \\ 0 \end{bmatrix}
\begin{bmatrix} 0 \\ 1 \\ 1 \end{bmatrix} $$
ist bspw. die erste Zeile \(0 1 1 0\), die zweite Zeile \(0 1 1 1\) und die dritte Zeile \(1 1 0 1\). Wir interpretieren nun jede Zeile als Binärzahl und betrachten die Sprache $$ Sum = \{ w \in \Sigma^* \mid \text{ die unterste Zeile ist Summe der oberen Zeilen} \} $$ In dem oben notierten Wort aus vier Symbolen ist dies der Fall, es wäre also in \(Sum\). Wir fragen nun: Ist \(Sum\) regulär?
Um ein Gefühl für die Sprache zu bekommen, kann man mit einigen kurzen Worten z.B. der Länge drei oder vier arbeiten und sich überlegen, was ein Automat tun müsste, wenn er diese Worte akzeptieren oder ablehnen sollte. An dieser Stelle kann man bemerken, dass die Behandlung des Übertrags problematisch ist. Der Automat liest das Wort ja von links nach rechts, kann hier aber scheinbar nicht bemerken, dass an einer Stelle eine richtige Rechnung stattfindet, da diese ggf. nur richtig ist, wenn man einen Übertrag hat, der ja aber erst später in dem Wort kommt. Würden wir das Wort von hinten lesen, wäre es einfacher. Wir könnten dann an jeder Stelle des Wortes, ganz so wie wir es beim schriftlichen Addieren machen, überprüfen, ob die Rechnung an dieser Stelle richtig ist und ob es einen Übertrag gibt. Wir ändern daher zunächst die Aufgabenstellung. Statt \(Sum\) zu betrachten, betachten wir nun die Menge aller Wörter \(w\), die umgedreht (also von rechts nach links gelesen) gerade in \(Sum\) sind. Diese Menge nennen wir \(Sum^R\) (\(R\) für Rückwärts). Hat man z.B. ein Wort \(w = abb\), dann ist \(w^R = bba\) und hat man eine Menge von Worten \(M\), dann ist \(M^R = \{w^R \mid w \in M\}\).
Statt nun zu versuchen \(Sum\) als regulär nachzuweisen, wollen wir nun also zeigen, dass \(Sum^R\) regulär ist. (Später werden wir sehen, dass für jede reguläre Sprache \(M\), \(M^R\) regulär ist (und umgekehrt). Daraus folgt dann, dass \(Sum\) regulär ist. Hier wollen wir es jetzt aber dabei belassen, darüber nachzudenken, ob \(Sum^R\) regulär ist.)
Mit der Idee von eben, \(Sum^R\) zu betrachten gelangen wir weiter. Wir lesen nun quasi eine binäre Addition von rechts nach links und können an jeder Stelle prüfen, ob richtig gerechnet wird. Falls dabei ein Übertrag auftritt, dann merken wir uns diesen im Zustand. Da es nur die Möglichkeit für einen Übertrag von \(0\) oder von \(1\) gibt, sind dies nur zwei Informationen und wir kommen mit endlich vielen Zuständen aus! Wir beginnen in einem Startzustand \(z_0\), mit dem wir gleichzeitig Übertrag \(0\) symbolisieren wollen. Kommt nun als erster Buchstabe ein Vektor wie \((0,0,0)\) oder \((1,0,1)\) (für die bessere Lesbarkeit schreiben wir die Vektoren hier als Zeilen; das erste Element im Vektor entspricht der ersten Zeile, das zweite Element der zweiten Zeile und das dritte Element der dritten Zeile), so können wir in \(z_0\) bleiben, denn in beiden Fällen ist die dritte Zeile (bzw. das dritte Element, in der Schreibweise als Tupel von eben) Summe der ersten beiden Zeilen (der ersten beiden Elemente) und es gibt keinen Übertrag. Entsprechendes gilt für \((0,1,1)\).
Bei \((1,1,0)\) hingegen stimmt zwar die Addition, wir haben aber einen Übertrag, d.h. wir müssen den Zustand wechseln. Hierfür erstellen wir einen neuen Zustand \(z_1\), in dem wir uns merken, dass wir Übertrag \(1\) haben. Alle anderen Symbole wie z.B. \((0,0,1)\) oder \((1,1,1)\) entsprechen Fehlern in der Rechnung, denn wenn wir keinen Übertrag haben (wir sind ja noch in \(z_0\)), dann ist \(0 + 0\) nicht \(1\) und \(1+1\) auch nicht. Analog für die anderen beiden fehlenden Symbole. Diese vier Symbole führen also in einen neuen (Fehler-)Zustand. Der Fehlerzustand hat zudem für jedes \(x \in \Sigma\) eine Kante zu sich selbst. Hier kann das Wort also zu Ende gelesen werden, wird aber nicht akzeptiert.
In \(z_1\) haben wir nun Übertrag \(1\) und wir gehen wieder alle Symbole durch und prüfen, ob die Rechnung an dieser Stelle stimmt. Dabei beachten wir aber den Übertrag von \(1\). So bleiben wir z.B. mit \((1,0,0)\) in \(z_1\), denn \(1 + 0\) ist zwar \(1\), aber wenn nun noch der Übertrag \(1\) hinzukommt, so haben wir richtigerweise in der dritten Zeile eine \(0\) und merken uns wieder den Übertrag von \(1\) (in \(z_1\)). Analog für \((0,1,0)\) und \((1,1,1)\). Das Symbol \((0,0,1)\) führt nun zurück zu \(z_0\), denn \(0+0\) plus den Übertrag ergibt \(1\), aber wir haben nun keinen Übertrag mehr, den wir uns merken müssten und gehen zurück nach \(z_0\). Die anderen vier Symbole führen wieder in den Fehlerzustand, da hier ein Fehler in der Rechnung aufgetreten ist. Zuletzt wählen wir noch \(z_0\) als Endzustand, da wir nur Worte akzeptieren wollen, die korrekte Rechnungen sind, bei denen also auch kein Übertrag mehr besteht. Dies ergibt den abgebildeten Automaten. Dieser ist schon recht kompliziert und seine Korrektheit ist nicht sofort ersichtlich. Daher ist hier ein nachvollziehbarer Beweis von \(L(A) = Sum^R\) dringend nötig.
Wir teilen den Beweis wieder in zwei Richtungen auf. In beiden Richtungen führen wir einen induktiven Beweis über die Wortlänge.
Wir zeigen per Induktion über die Wortlänge \(n\): Für \(w = w_1 \ldots w_n\) gilt:
Wenn \(w\) eine korrekte Rechnung mit Übertrag 0 ist, dann liest \(A\) das Wort \(w\) und endet in \(z_0\).
Wenn \(w\) eine korrekte Rechnung mit Übertrag 1 ist, dann liest \(A\) das Wort \(w\) und endet in \(z_1\).
Wobei wir hier mit korrekte Rechnung meinen, dass in \(w^R\) die erste und zweite Zeile zusammenaddiert gerade die dritte Zeile ergibt, wobei am Ende noch ein Übertrag von \(0\) oder \(1\) bestehen kann. Man beachte insb. dass wir von einer korrekten Rechnung sprechen, auch wenn das Wort noch umgedreht werden muss.
Induktionsanfang: \(w = w_1\). Nur in den Fällen \((0,0,0), (1,0,1)\) und \((0,1,1)\) ist \(w\) eine korrekte Rechnung mit Übertrag \(0\). \(A\) liest hier \(w\) und endet in \(z_0\). In dem Fall \((1,1,0)\) ist \(w\) eine korrekte Rechnung mit Übertrag \(1\). \(A\) liest in diesem Fall \(w\) und endet in \(z_1\). In den übrigen Fällen \((1,0,0), (0,1,0), (0,0,1)\) und \((1,1,1)\) ist \(w\) keine korrekte Rechnung und es ist nichts zu zeigen. (Wir sind hier also einfach alle Möglichkeiten für \(w_1 \in \Sigma\) durchgegangen und haben gezeigt, dass die geforderten "wenn ... dann"-Beziehungen gelten.)
Induktionsannahme: Gelte die Behauptung für ein \(n \geq 1\).
Induktionsschritte: Sei nun \(w = w_1 \ldots w_{n+1}\) ein Wort der Länge \(n+1\). Wir unterscheiden die zwei Fälle.
\(w = w_1 \ldots w_{n+1}\) ist eine korrekte Rechnung mit Übertrag \(0\). Wir müssen zeigen, dass \(A\) das Wort \(w\) lesen kann und dann in \(z_0\) ist. Wir betrachten \(w' := w_1 \ldots w_n\). Diese Rechnung muss auch korrekt sein, da \(w_1 \ldots w_{n+1}\) korrekt ist. D.h. \(w'\) ist eine korrekte Rechnung und hat Übertrag \(0\) oder \(1\). Wir wenden auf \(w'\) die Induktionsannahme an. Hat \(w'\) Übertrag \(0\) so enden wir (nach Induktionsannahme) in \(z_0\). Da \(w = w_1 \ldots w_{n+1}\) eine korrekte Rechnung mit Übertrag \(0\) ist, kann, da auch \(w'\) eine korrekte Rechnung mit Übertrag \(0\) ist, \(w_{n+1}\) nur eines der Symbole \((0,0,0), (1,0,1)\) oder \((0,1,1)\) sein, also gerade jene Symbole, die im Automaten Schleifen an \(z_0\) sind. \(A\) bleibt also in \(z_0\), was wir ja gerade zeigen wollten.
Hat \(w' = w_1 \ldots w_n\) Übertrag \(1\), so enden wir nach Induktionsannahme in \(z_1\). Damit \(w\) nun Übertrag \(0\) hat, gibt es für \(w_{n+1}\) nur den Fall \((0,0,1)\). Diese Kante führt uns im Automaten aber wieder nach \(z_0\), womit wir insgesamt gezeigt haben, dass \(A\) das Wort \(w\) lesen kann und in \(z_0\) endet (ausgehend von einer Korrekten Rechnung \(w\) mit Übertrag \(0\)).
Im zweiten Fall ist \(w = w_1 ... w_{n+1}\) eine korrekte Rechnung mit Übertrag \(1\). Wir müssen nun zeigen, dass \(A\) das Wort \(w\) lesen kann und dann in \(z_1\) ist. Wie eben betrachten wir \(w' := w_1 \ldots w_n\). \(w'\) muss nun ebenfalls wieder korrekt sein und hat Übertrag \(0\) oder \(1\). Hat \(w'\) Übertrag \(0\), so liest \(A\) nach Induktionsannahme das Wort \(w'\) und endet in \(z_0\). Nur \(w_{n+1} = (1,1,0)\) führt nun dazu, dass \(w\) eine korrekte Rechnung mit Übertrag \(1\) ist. Dieses Symbol kann \(A\) lesen und ist dann in \(z_1\), was wir in diesem Fall ja gerade wieder zeigen wollten.
Hat \(w'\) hingegen Übertrag \(1\), so liest \(A\) das Wort \(w'\) nach Induktionsannahme und ist dann in \(z_1\). Nun muss \(w_{n+1}\) eines der Symbole \((1,0,0), (0,1,0)\) oder \((1,1,1)\) sein, damit \(w\) eine korrekte Rechnung mit Übertrag \(1\) ist. Diese Symbole überführen den Automaten \(A\) aber gerade von \(z_1\) nach \(z_1\) und damit haben wir auch hier gezeigt, dass \(A\) das Wort \(w\) lesen kann und dann in \(z_1\) ist.
Damit ist die Induktionsbehauptung bewiesen.
Sei nun \(w \in Sum^R\), dann wissen wir dass \(w\) in der Formulierung der Induktionsbehauptung eine korrekte Rechnung mit Übertrag \(0\) ist. Aus dem eben bewiesenen folgt dann, dass \(A\) das Wort \(w\) lesen kann und dann in \(z_0\) ist. Da \(z_0\) ein Endzustand ist, akzeptieren wir und wir haben \(w \in L(A)\). Damit ist \(Sum^R \subseteq L(A)\) gezeigt.
Für die Rückrichtung, könnten wir eine weitere Induktionsbehauptung aufstellen, die diesmal von der Rechnung des Automaten ausgeht. Diese könnte wie folgt lauten: Liest \(A\) das Wort \(w = w_1 ... w_n\), so gilt: Wenn \(A\) in \(z_0\) endet, so ist \(w\) eine korrekte Rechnung mit Übertrag \(0\), wenn \(A\) in \(z_1\) endet, so ist \(w\) eine korrekte Rechnung mit Übertrag \(1\) und wenn \(A\) in \(z_e\) endet, so ist \(w\) eine inkorrekte Rechnung. Dies könnte man ähnlich wie eben beweisen. Man kann aber erkennen, dass dies im Kern gerade die Umkehrungen der "wenn ... dann"-Beziehungen in der ersten Induktionsbehauptung sind. Daher werfen wir noch einmal einen Blick auf diese. Wenn wir dort als dritten Fall noch hinzunehmen
Wenn \(w\) eine inkorrekte Rechnung ist, dann liest \(A\) das Wort \(w\) und endet in \(z_e\).
so müssen wir lediglich im Induktionsanfang noch ausführen, dass die verbleibenden Symbole inkorrekte Rechnungen sind und den Automaten nach \(z_e\) führen und im Induktionsschritt kommt der dritte Fall hinzu, dass \(w\) eine inkorrekte Rechnung ist. Hier zeigt man aber auch schnell, dass wir in \(z_e\) enden. Entweder ist schon die kürzere Rechnung \(w'\) eine inkorrekte Rechnung und wir verbleiben in \(z_e\) oder wir gelangen von \(z_0\) oder \(z_1\) nach \(z_e\), wenn \(w_{n+1}\) für die inkorrekte Rechnung sorgt.
Haben wir dies nun bewiesen, so decken die drei Fälle, dass \(w\) eine korrekte Rechnung mit Übertrag \(0\) oder \(1\) ist und dass \(w\) eine inkorrekte Rechnung ist, alle Möglichkeiten für \(w\) ab, d.h. aus den "wenn ... dann"-Beziehungen folgen sofort "genau dann, wenn"-Beziehungen es gilt also sogar
\(w\) ist eine korrekte Rechnung mit Übertrag 0 genau dann, wenn \(A\) das Wort \(w\) liest und in \(z_0\) endet.
\(w\) ist eine korrekte Rechnung mit Übertrag 1 genau dann, wenn \(A\) das Wort \(w\) liest und in \(z_1\) endet.
\(w\) ist eine inkorrekte Rechnung genau dann, wenn \(A\) das Wort \(w\) liest und in \(z_e\) endet.
Damit folgt nun ganz schnell auch die Teilmengenbeziehung \(L(A) \subseteq Sum^R\). Sei dazu \(w \in L(A)\), dann liest \(A\) also \(w\) und endet in \(z_0\). Nach obigem ist dann \(w\) eine korrekte Rechnung mit Übertrag \(0\), also \(w \in Sum^R\).
Dadurch, dass wir uns soviel Arbeit bei der Induktion(sbehauptung) gemacht haben, gingen die beiden Teilmengenbeziehungen dann ganz schnell.
Damit haben wir \(L(A) = Sum^R\) bewiesen. Wir wissen nun zwar noch nicht, ob auch \(Sum\) regulär ist. Dies
wird aber ganz schnell aus der später folgenden Behandlung von Abschlusseigenschaften folgen.
Dieses kompliziertere Beispiel schließt diesen Abschnitt ab. Man beachte, wie hier wieder
eine Induktion über die Wortlänge als Beweistechnik eingesetzt wurde.
Zusammengefasst haben wir in diesem Abschnitt zwei Techniken zur Konstruktion von DFAs kennengelernt und an Beispielen betrachtet.
Die erste Technik beruht darauf, sich zu einer gegebenen Sprache \(M\) zu überlegen, mit welchen Informationen man arbeiten kann, um Worte aus \(M\) identifizieren zu können, und wie man diese Informationen aktualisieren kann. Wichtig ist hierbei, dass man nur endliche viele Informationen hat, damit endlich viele Zustände ausreichen, um diese zu speichern, und dass diese durch die Kantenübergänge gut aktualisiert werden können. Manchmal wird bei dieser Technik ein Teil konstruiert, der gar nicht vom Startzustand aus erreichbar ist. Dieser Teil kann dann später entfernt werden.
Die zweite Technik beruht darauf, sich schrittweise zu überlegen, was in jedem Zustand bei jedem Eingabesymbol passiert. Man beginnt hier im Startzustand und erzeugt dann sukzessive weitere Zustände, sofern nötig. Kritisch hier ist zu bemerken, wann man von einem Zustand zu einem bereits generierten Zustand zurück kann. Nur dann bricht das Verfahren ab. Sonst generiert man immer weiter neue Zustände. Die mit der zweiten Technik erstellten endlichen Automaten sind im Allgemeinen initial zusammenhängend und vollständig.
Egal wie man nun zu einem Automaten \(A\) kommt. Immer gilt: \(L(A) = M\) ist bisher nur eine Behauptung, die dann noch zu zeigen ist. In den Beispielen haben wir die Argumentation "nach Konstruktion" gesehen und einen Induktionsbeweis über die Wortlänge. Die Formulierung "nach Konstruktion" ist oft nützlich, sollte aber nur gewählt werden, wenn man Dinge tatsächlich schnell am Diagramm sehen kann oder wenn man vorher die Idee der Konstruktion gut erläutert hat und hieraus tatsächlich etwas abgeleitet werden kann. Wenn man z.B. einen Automaten mit zwei Endzuständen \(z_5\) und \(z_9\) hat, dann kann man gut sagen, dass man nach Konstruktion bei einem akzeptierten Wort in \(z_5\) oder \(z_9\) endet. Dies kann man gut ablesen. Wenn man aber einfach sagt, dass man jedes Wort einer Sprache \(M\) nach Konstruktion akzeptiert, dann ist dies in den meisten Fällen zu wenig.
Wenn die Automaten komplizierter werden, dann hilft einem oft ein Induktionsbeweis über die Wortlänge. Man kann dann im Induktionsschritt meist ausnutzen, dass man nach Lesen der ersten \(n\) Buchstaben in einem der Zustände ist und die Eigenschaft dieses Zustands nutzen (z.B. dass man in diesem Zustand nur endet, wenn das bisherige Wort gerade viele \(0\)en hat oder ähnliches; was man hier nutzen kann, hängt von der Induktionsbehauptung ab, die man zeigen will). Danach ist es dann oft möglich mit der Konstruktionsidee zu arbeiten und hier kann dann ggf. auch wieder auf die Konstruktion verwiesen werden.
Zeitlimit: 0
Quiz-Zusammenfassung
0 von 2 Fragen beantwortet
Fragen:
1
2
Informationen
Hier ein paar Fragen zur Konstruktion von DFAs.
Sie haben das Quiz schon einmal absolviert. Daher können sie es nicht erneut starten.
Quiz wird geladen...
Sie müssen sich einloggen oder registrieren um das Quiz zu starten.
Sie müssen erst folgende Quiz beenden um dieses Quiz starten zu können:
Ergebnis
0 von 2 Frage korrekt beantwortet
Ihre Zeit:
Zeit ist abgelaufen
Sie haben 0 von 0 Punkten erreicht (0)
Kategorien
Nicht kategorisiert0%
1
2
Beantwortet
Vorgemerkt
Frage 1 von 2
1. Frage
Wie viele Informationen kann man in einem DFA speichern?
Üblicherweise wollen wir nun zu einer Sprache \(M\), die uns interessiert, einen DFA \(A\) konstruieren, der diese Sprache akzeptiert, d.h. einen mit \(L(A) = M\). Eine Sprache, die uns interessieren könnte, könnte z.B. die Menge aller Wörter sein, die mit \(a\) beginnen oder die Menge aller Wörter, die das Wort \(aa\) als Teilwort enthalten.
Die Sprachen erscheinen vielleicht etwas künstlich. Die benutzten Symbole wie \(a\), \(b\) usw. dienen aber üblicherweise nur als Abstraktion für Aktionen wie 'Schalter betätigen' oder 'Speicher löschen'.
Außerdem lassen sich kompliziertere Sprachen formulieren. Stellt man sich den Automaten nicht mehr so vor, dass er ein Wort von einem Band liest, sondern dass er Aktionen ausführt (jedes Symbol des Eingabealphabets steht also für eine Aktion), so kann man z.B. versuchen die Anforderung 'zwischen zwei Aktionen \(a\) soll immer genau einmal die Aktion \(b\) passieren' als Sprache zu formulieren und dann versuchen einen Automaten dazu zu konstruieren. Bei solchen Formulierungen ist einfacher einzusehen, dass sie als Anforderungen in Anwendungen auftreten. Sie sind allerdings auch schwieriger und treten daher in einführenden Beispielen noch nicht auf.
Der zur Menge \(M\) konstruierte Automat \(A\) soll genau die Wörter in \(M\) akzeptieren (nicht mehr, nicht weniger), denn sonst gilt nicht \(L(A) = M\). Dies ist aber wichtig, denn hat man nur \(L(A) \subset M\), dann akzeptiert der Automat nicht jedes Wort aus \(M\) und ist daher fehlerhaft. Hat man nur \(M \subset L(A)\), dann akzeptiert der Automat weitere Worte, die er eigentlich nicht akzeptieren soll, was ebenfalls fehlerhaft ist.
Ein verbreitetes Problem zu Anfang ist, dass man das Gefühl hat, eine der Richtungen (\(L(A) \subseteq M\) oder \(M \subseteq L(A)\)) würde genügen. Meist stört man sich dann nicht daran, dass der Automat zu viel oder zu wenig kann. Nehmen wir einmal das Beispiel der Menge \(M\) aller Worte, die mit \(a\) beginnen. Wir wollen also einen Automaten \(A\), der ein Wort \(w\) genau dann akzeptiert, wenn es mit \(a\) beginnt. Ansonsten soll es abgelehnt werden. Hat man jetzt nur \(L(A) \subseteq M\) und gilt tatsächlich nicht \(L(A) = M\) (d.h. es ist \(L(A) \subset M\)), dann gibt es Wörter, die mit \(a\) beginnen, die der Automat nicht akzeptiert. Wir wollten ja aber gerade, dass er alle Worte akzeptiert, die mit \(a\) beginnen. Mit einem solchen Automaten können wir also nicht zufrieden sein. Haben wir andersherum nur \(M \subset L(A)\) erreicht, so akzeptiert der Automat neben den Worten, die mit \(a\) beginnen, noch weitere, womit wir ebenfalls nicht zufrieden sein können.
Man stelle sich vor, in der Sprache \(M\) sind die Möglichkeit Münzen korrekt in einen Automaten zu werfen (z.B. für eine Fahrkarte für den Bus; nehmen wir an die Karte kostet \(50\) Cent und es gibt \(10\) und \(20\) Cent Münzen (symbolisiert durch \(a\) und \(b\)). Dann ist z.B. die Folge \(abb\) (eine \(10\)er, zwei \(20\)er Münzen) ein korrekter Münzeinwurf, die Folge \(bbb\) hingegen nicht, wobei wir die Möglichekeit, Wechselgeld zurückzugeben, nicht beachten wollen). \(L(A) \subset M\) bedeutet dann, dass es Möglichkeiten gibt, Münzen korrekt einzuwerfen, die der Automat nicht akzeptiert (das Geld behält er aber vielleicht trotzdem ein, in jedem Fall wird der Kunde genervt sein). \(M \subset L(A)\) bedeutet, dass der Automat noch Folgen akzeptiert, die nicht vorgesehen sind. Dies könnte für den Anbieter schlecht sein, wenn der Kunde die Fahrkarte z.B. auch kriegt, wenn er noch gar nicht genug Geld eingeworfen hat.
In diesem Abschnitt wollen wir uns zwei Konstruktionsmethoden für DFAs ansehen und uns mit den Beweisen von \(L(A) = M\) beschäftigen, denn auch wenn man einen Automaten \(A\) konstruiert hat, dann ist \(L(A) = M\) zunächst nur eine Behauptung oder Vermutung. Diese ist dann noch zu beweisen.
Der hier aus didaktischen Gründen auftreten Fall, zu einem gegebenen Automaten \(A\) die Menge \(M\) mit \(L(A) = M\) zu ermitteln (und dies zu beweisen), tritt in Anwendungen kaum auf. Dies wäre ungefähr so als müsste man zu unkommentierten Code, dessen Bedeutung ermitteln. Zum Erlernen der Funktionsweise von Automaten ist dies aber ein ganz praktisches Vorgehen, daher tritt dies hier und in der Literatur meist ein paar Mal auf.
In den Beispielen dieses Abschnitts wird man an mehreren Stellen vielleicht denken, dass man die Lösung doch ohnehin schon sieht oder dass bei beiden Richtungen des Beweises von \(L(A) = M\) das gleiche passiert.
Dass man die Lösung schon sieht, mag an einigen Stellen stimmen. Die einfachen Automaten und Sprachen dienen ja aber gerade zur Übung, sie sollen das Vorgehen eintrainieren, dass man dann bei komplizierteren Automaten oder Sprachen oder auch bei fortgeschritteneren Automatenmodellen anwenden kann.
Der Eindruck, dass bei beiden Richtungen das gleiche passiert, entsteht zu Anfang schnell, ist aber falsch. Bei der einen Richtung zeigen wir \(L(A) \subseteq M\), also dass jedes Wort, das der Automat \(A\) akzeptiert, auch in \(M\) ist. Um dies zu zeigen gehen wir von einem Wort \(w \in L(A)\) aus und zeigen dann, dass auch \(w \in M\) gilt. Wir nutzen also nur die Eigenschaften, die ein Wort hat, das von dem Automaten \(A\) akzeptiert wird und versuchen daraus abzuleiten, dass dieses Wort auch in \(M\) ist.
Bei der anderen Richtung zeigen wir \(M \subseteq L(A)\), also dass jedes Wort, das in \(M\) ist, auch von \(A\) akzeptiert wird. Um dies zu zeigen gehen wir nun von einem Wort \(w \in M\) aus und zeigen dann, dass auch \(w \in L(A)\) gilt. Wir nutzen also nur die Eigenschaften, die ein Wort hat, das in \(M\) ist und versuchen daraus abzuleiten, dass dieses Wort auch in \(L(A)\) ist.
Der fälschliche Eindruck, dass hier das gleiche passieren würde entsteht bei den Beispielen zu Anfang dadurch, dass die Eigenschaften, die ein Wort hat, das von \(A\) akzeptiert wird und die Eigenschaft die ein Wort hat, das in \(M\) ist, meist sehr ähnlich sind und daher die Argumentation auch sehr ähnlich aussieht. Man mache sich aber in den folgenden Beispielen und auch bei der eigenen Arbeit aber klar, dass tatsächlich beim Beweis von z.B. \(L(A) \subseteq M\) von einem Wort \(w \in L(A)\) ausgegangen wird und dann mittels Eigenschaften die ein solches Wort hat (wobei sich diese Eigenschaften aus dem speziellen Automaten \(A\) und der Art wie Automaten akzeptieren ergeben) argumentiert wird, um letztendlich zu zeigen, dass das Wort auch in \(M\) ist. Bei späteren, komplizierteren Sprachen und Automaten wird es dann wichtig sein, diese klare Trennung erlernt zu haben.
(In einigen Fällen kann man auch gut mit ``genau dann, wenn'' Beziehungen zeigen, dass \(w \in L(A)\) gilt genau dann, wenn \(w \in M\) gilt und ist dann sofort fertig. Wir machen dies hier aber höchstens in Ausnahmefällen, um die obige klare Trennung zu betonen.)
Ein erstes Beispiel
Betrachten wir als erstes Beispiel den abgebildeten Automaten.
Nachdem man den Automaten etwas untersucht hat, kommt man nach einigem Nachdenken und Ausprobieren einzelner Worte zu der Vermutung, dass die akzeptierte Sprache gerade \(\{a\} \cdot \{b\}^* \cdot \{a\}\) sein könnte. Zur Erleichterung der Notation setzen wir \(M := \{a\} \cdot \{b\}^* \cdot \{a\}\) und nennen den Automaten \(A\). Unsere Vermutung oder Behauptung ist nun also, dass \(L(A) = M\) gilt.
Auch wenn man sich bei diesem kleinen Beispiel vielleicht sehr sicher ist, dass diese Vermutung stimmt, so ist sie dennoch zu beweisen (und insb. für spätere, kompliziertere Fälle wird es wichtig sein, das Vorgehen zu beherrschen). Wir teilen den Beweis von \(L(A) = M\) in zwei Teile auf. Die beiden nachfolgenden Teilbeweise sind absichtlich sehr ausführlich. Im Anschluss finden sich beide Richtungen mit kürzeren Argumentationen bewiesen. Wir wollen das hier aber zunächst ganz ausführlich machen, damit man sehen kann, was im einzelnen argumentiert werden muss.
Beweis von L(A) = M
Zuerst wollen wir \(L(A) \subseteq M\) beweisen. Wir wollen also zeigen, dass jedes Wort, das der Automat \(A\) akzeptiert, auch in \(M\) enthalten ist. Betrachten wir also ein beliebiges Wort \(w\), das von \(A\) akzeptiert wird, also ein \(w \in L(A)\). Wir wissen, dass der Automat \(A\) in seinem Startzustand \(z_0\) beginnen muss. Wir wissen ferner, dass \(w\) akzeptiert wird, also wissen wir, dass \(A\) das Wort \(w\) zu Ende lesen kann und dann in einem Endzustand ist (nur dann akzeptiert \(A\) ein Wort). Da es nur einen Endzustand gibt, wissen wir, dass \(A\) das Wort \(w\) lesen kann und er dann in \(z_2\) ist. Damit wissen wir schon, dass wir von der Konfiguration \((z_0, w)\) irgendwie (d.h. mittels möglicher Übergänge in \(A\)) in die Konfiguration \((z_2, \lambda)\) gelangen. Betrachten wir den Automaten weiter, so sehen wir, dass aus \(z_0\) nur eine \(a\)-Kante heraus führt und nach \(z_2\) nur eine \(a\)-Kante hinein und dass in \(z_2\) nicht mehr gelesen werden kann. Die \(a\)-Kante aus \(z_0\) heraus führt zudem nach \(z_1\) und die \(a\)-Kante nach \(z_2\) kommt von \(z_1\). Insgesamt wissen wir damit, dass \(w\) mit einem \(a\) beginnen und mit einem \(a\) enden muss und wir wissen dass dies nicht das gleiche Symbol in \(w\) sein kann ([/latex]w[/latex] also aus mindestens zwei \(a\) besteht). Damit ist \(w\) von der Form \(a \cdot v \cdot a\) mit \(v \in \{a,b\}^*\). Wir wissen damit bisher, dass beim Lesen von \(w = ava\) folgende Konfigurationsübergänge passieren:
$$ (z_0, ava) \vdash (z_1, va) \vdash \cdots \vdash (z_1, a) \vdash (z_2, \lambda).$$Die Stelle mit den Punkten ist nun noch unbekannt. Wir wissen nun, dass wir von \(z_1\) ausgehend mit erlaubten Übergängen im Automaten nach \(z_1\) gelangen und dabei das Teilwort \(v\) komplett lesen. Ein weiterer Blick auf den Automaten zeigt uns, dass es in \(z_1\) zwei Kanten gibt, eine \(a\)– und eine \(b\)-Kante. Die \(a\)-Kante führt aber zu \(z_2\) und von dort kommen wir nicht mehr nach \(z_1\). Diese Kante kann uns beim Lesen von \(v\) also nicht helfen. Die \(b\)-Kante führt uns von \(z_1\) nach \(z_1\) und dies kann uns beim Lesen von \(v\) helfen. Da dies außerdem die einzige Kante ist (und sie nicht von \(z_1\) wegführt; dies würde eine weitere Analyse erforderlich machen) können wir schließen, dass wir von der Konfiguration \((z_1, va)\) zur Konfiguration \((z_1, a)\) nur über \(b\)-Kanten gelangen, d.h. \(v = b^n\) für ein \(n \geq 0\) (der Sonderfall \(v = 0\) ist auch möglich, wovon man sich schnell durch einen Blick auf den Automaten überzeugt). Damit haben wir argumentiert, dass, wenn \(w\) von \(A\) akzeptiert wird, \(w\) von der Form \(a \cdot b^n \cdot a\) für ein \(n \geq 0\) sein muss. Zur Erinnerung: Unser ursprüngliches Ziel ist es \(L(A) \subseteq M\) zu zeigen. Wir gehen also von einem \(w \in L(A)\) aus und wollen zeigen, dass \(w \in M\) gilt. Sei also \(w \in L(A)\), dann wissen wir nun, dass es ein \(n \geq 0\) gibt mit \(w = a \cdot b^n \cdot a\). Wegen \(a \in \{a\}\) und \(b^n \in \{b\}^*\) ist nun \(a \cdot b^n \cdot a \in \{a\} \cdot \{b\}^* \cdot \{a\}\), also \(w \in M\) und wir sind fertig.
Nun wollen wir noch \(M \subseteq L(A)\) beweisen. Wir wollen nun also zeigen, dass jedes Wort der Menge \(M\) auch vom Automaten \(A\) akzeptiert werden kann. Diese Richtung ist meist einfacher zu zeigen. Wir wählen ein beliebiges Wort aus \(M\) und zeigen durch Angabe von Konfigurationsübergängen, dass \(A\) das Wort zu Ende lesen kann und vom Start- in einen Endzustand gelangt (das Wort also akzeptiert). Da das Wort beliebig gewählt wurde, gilt es dann für alle Worte in \(M\) und wir sind fertig. Sei also \(w \in M\) beliebig gewählt, d.h. \(w\) ist aus \(\{a\} \cdot \{b\}^* \cdot \{a\}\) und aufgrund der Definition der Konkatenation und der Sternbildung wissen wir also, dass es ein \(n \geq 0\) gibt derart, dass \(w = ab^na\) ist.
Man beachte an dieser Stelle, dass wir \(w\) weiterhin beliebig gewählt haben. Die verschiedenen \(n\) führen dann zu verschiedenen Worten in \(M\). Hat man kompliziertere Sprachen, so sind oft Fallunterscheidungen nötig. Hat man z.B. als Sprache \(N := \{a\} \cdot (\{b\}^* \cup \{c\}^*) \cdot \{d\}\) und wählt wieder \(w \in N\) beliebig, so weiß man, dass \(w\) mit \(a\) beginnt und dass dann beliebig viele \(b\) \emph{oder} beliebig viele \(c\) folgen. Daran schließt sich dann in beiden Fällen noch ein \(d\) an. Man würde dann meist beide Fälle getrennt behandeln und für beide Fälle zeigen, dass der Automat die Worte akzeptiert. Man hat dann also die beliebig gewählten Worte in zwei Klassen zerlegt und für beide Klassen gezeigt, dass der Automat diese Worte akzeptiert. Da beide Klassen zusammen wieder die ganze Menge \(N\) ergeben, ist man dann fertig.
Nun legen wir \(w = ab^na\) dem Automaten \(A\) vor. Als Übergänge ergibt sich dann aufgrund der Konstruktion von \(A\) \[ (z_0, ab^na) \vdash (z_1, b^na) \vdash^* (z_1, a) \vdash (z_2, \lambda) \] wobei \(\vdash^*\) für endliche viele (auch \(0\)) Übergänge steht. Damit haben wir eine Erfolgsrechnung auf \(A\) und akzeptieren \(w\), also gilt \(w \in L(A)\).
Einigen ist der Beweis oben bestimmt zu länglich. Wir waren dort absichtlich ganz besonders ausführlich. Der Beweis geht aber auch viel kürzer.
Wir zeigen zuerst \(L(A) \subseteq M\). Sei also \(w \in L(A)\). Nach Konstruktion muss \(w\) mit \(a\) beginnen und mit \(a\) enden, denn die einzige Kante aus dem Startzustand \(z_0\) heraus ist mit einem \(a\) beschriftet, ebenso wie die einzige Kante in den einzigen Endzustand \(z_2\) hinein. Da diese Kanten zudem nach \(z_1\) gehen bzw. von \(z_1\) kommen, muss ein Wort, das \(A\) zwischen diesen beiden \(a\) liest, den Automaten von \(z_1\) nach \(z_1\) überführen. Da es an \(z_1\) nur eine \(b\)-Schleife gibt, folgt \(w \in \{a\}\{b\}^*\{a\}\) und damit \(w \in M\).
Sei nun \(w \in M\), dann gibt es ein \(n \geq 0\) mit \(w = a \cdot b^n \cdot a\). Damit ergibt sich \[ (z_0, ab^na) \vdash (z_1, b^na) \vdash^* (z_1, a) \vdash (z_2, \lambda) \] woraus \(w \in L(A)\) folgt.
Nachfolgend werden die Beweise in ähnlichen Beispielen an vielen Stellen deutlich kürzer ausfallen. Es ist aber eine gute Übung sich zu Anfang jedes Argument sehr kleinschrittig zu überlegen und aufzuschreiben und sich auch später bei schnelleren Argumentationen, genau zu überlegen, ob die Schritte nachvollziehbar sind (sowohl wenn man selbst schneller vorgeht als auch wenn man schneller voranschreitende Beweise liest).
Da es nun also scheinbar unterschiedlich lange Beweise für die gleiche Aussage gibt, kann man sich an dieser Stelle fragen, ob dieser Unterschied überhaupt erlaubt ist. Ist der kurze Beweis erlaubt? Sind beide Beweise richtig? Und falls ja, sollte man selbst lieber lange oder lieber kurze Beweise führen?
Wichtig beim Beweisen ist, dass die einzelnen Argumentationsschritte für den Leser nachvollziehbar sind. Das eigentliche Ziel bei einem Beweis ist ja, dass der Beweis den Leser von der Richtigkeit der Aussage überzeugt und das durch logisch nachvollziehbare Argumente. Ein kürzerer Beweis erfordert daher im Allgemeinen mehr Kenntnisse (oder mehr Mitdenken) beim Leser. Oben könnte man z.B. sagen, dass jedes Wort, das der Automat liest, mit \(a\) beginnen muss oder mit \(a\) enden muss. Will man dem Leser mehr Informationen mitgeben, schreibt man vielleicht noch dazu, dass dies nach Konstruktion gilt. Noch mehr Hilfe gibt man, wenn man noch notiert, dass dies an dem Start- und dem Endzustand liegt bzw. an den Kanten die von ihnen kommen bzw. zu ihnen hinführen. Welche Detailtiefe man wählt hängt sehr von der anvisierten Leserschaft ab und von der eigenen Übung.
Sowohl der lange als auch der kurze Beweis oben sind also richtig. Die kurzen Beweise erwarten aber mehr vom Leser. Ist man in einem Themengebiet neu, so lohnt es sich stets in den Beweisen sehr ausführlich vorzugehen und jeden Argumentationsschritt möglichst ausführlich zu begründen. Dies ist eine gute Übung für einen selbst und es ermöglicht dem Leser gut zu folgen. Für Korrekturen ist insb. von Vorteil, dass man einfacher sagen kann, wo ggf. ein Denkfehler besteht. Zu Anfang gilt daher: bei jedem Beweise an jeder Stelle einmal die `Warum?'-Frage stellen. Warum gilt dieses Argument? Wenn die Antwort darauf zu lang ist, dann sollte man hier noch ausführlicher sein.
Noch ein Beispiel
Wir wollen als weiteres Beispiel den folgenden Automaten betrachten und diesmal mit einer Annahme beginnen, die sich während des Beweises als falsch herausstellt. Das Beispiel ist zwar wieder so klein, dass man die richtige Sprache gleich erkennen kann, es geht hier aber darum, die Vorgehensweise einzuüben und dafür bieten sich kleinere Beispiele an. Außerdem werden wir hier eine Beweisidee kennenlernen, die an verschiedenen Stellen nützlich sein kann. Später folgt dann auch noch ein größeres und komplizierteres Beispiel.
Angenommen wir vermuten nun, dass die von diesem Automaten akzeptierte Sprache die Menge \(M := \{0,1\}^* \cdot \{1\} \cdot \{0,1\}^*\) ist. Wir vermuten also, dass \[ L(A) = \{0,1\}^* \cdot \{1\} \cdot \{0,1\}^* = M\] gilt.
Tatsächlich ist die akzeptierte Sprache natürlich \(\{0\}^* \cdot \{1\}\) und wir haben beim Aufstellen von \(M\) einen Fehler gemacht. Dieses negative Beispiel soll noch einmal illustrieren, wie wir beim Beweis von \(L(A) = M\) vorgehen und das Fehler beim Aufstellen von \(M\) passieren können, die dann beim Beweisen (hoffentlich) auffallen und korrigiert werden können.
Wir gehen so vor wie eben und versuchen, die zwei Teilmengenbeziehungen zu zeigen.
Beweis von L(A) = M
\(L(A) \subseteq \{0,1\}^* \cdot \{1\} \cdot \{0,1\}^* = M\). Sei \(w \in L(A)\), dann wird \(w\) von \(A\) akzeptiert. Da \(z_1\) der einzige Endzustand ist, muss \(w\) auf \(1\) enden, da die einzige Kante in \(z_1\) hinein mit \(1\) beschriftet ist. Vorher war der Automat in \(z_0\), wo nur \(0\)en gelesen werden können. D.h. \(w\) hat die Form \(w = u1\) mit \(u \in \{0\}^*\). Damit gilt auch \(w \in M\). (Man kann schon hier merken, dass \(M\) wohl zu 'groß' ist. Allerdings muss man es hier noch nicht merken. Die Teilmengenbeziehung \(L(A) \subseteq M\) gilt nämlich!)
\(M = \{0,1\}^* \cdot \{1\} \cdot \{0,1\}^* \subseteq L(A)\). Sei \(w \in M\), dann lässt sich \(w\) zerlegen in \(w = x_1 \cdot x_2 \cdot x_3\) mit \(x_1, x_3 \in \{0,1\}^*\) und \(x_2 = 1\). Da in \(w\) eine \(1\) auftritt, muss es auch eine Stelle geben, an der die \(1\) das erste Mal auftritt, d.h. \(w\) lässt sich sogar zerlegen in \(w = x_1′ \cdot x_2′ \cdot x_3′\) mit \(x_1′ \in \{0\}^*\), \(x_2′ = 1\) und \(x_3′ \in \{0,1\}^*\). Legen wir \(w\) nun \(A\) als Eingabe vor, so gilt zunächst \((z_0, x_1′ \cdot 1 \cdot x_3′) \vdash^* (z_0, 1 \cdot x_3′)\) und dann \((z_0, 1 \cdot x_3′) \vdash (z_1, x_3′)\).
An dieser Stelle bemerken wir nun, dass wir einen Fehler gemacht haben. Da es in \(z_1\) keine Kante gibt, blockieren wir nun nämlich. Das Wort wird also gar nicht akzeptiert!
Aus dem Beweis(versuch) von eben ergibt sich auch gleich ein Gegenbeispiel. Das Wort \(010\) kann z.B. von dem Automaten nicht akzeptiert werden, ist aber in \(M\).
Im besten Fall kann man nach solch einem Beweisversuch auf eine bessere Idee für \(M\) kommen und einen neuen Beweisversuch starten. Wir vermuten nun, dass \(M‘ := \{0\}^* \cdot \{1\}\) die akzeptierte Sprache ist, unsere Vermutung ist nun also $$ L(A) = \{0\}^* \cdot \{1\} = M‘. $$
Beweis von L(A) = M
\(L(A) \subseteq \{0\}^* \cdot \{1\} = M‘\). Dies zeigt man genau wie eben.
\(M‘ = \{0\}^* \cdot \{1\} \subseteq L(A)\). Sei \(w \in M‘\), dann lässt sich \(w\) zerlegen in \(w = u1\) mit \(u \in \{0\}^*\). Es gilt nun \((z_0, u1) \vdash^* (z_0, 1) \vdash (z_1, \lambda)\) und da \(z_1\) ein Endzustand ist, gilt \(w \in L(A)\), was zu zeigen war.
Nun gelingt der Beweis und wir haben \(L(A) = M‘\) gezeigt.
Wichtige Beweisidee
Obwohl der erste Beweisversuch nicht gelang, konnte man dort eine wichtige Beweisidee sehen. Wissen wir, dass in einem Wort \(w\) ein Symbol oder eine Zeichenkette auftritt, wissen wir also z.B. das in \(w\) eine \(1\) auftritt oder die Zeichenkette \(000\) als Teilwort, dann wissen wir auch, dass dies an einer Stelle in \(w\) das erste Mal passiert. Dies hilft oft bei der Zerlegung von \(w\) in Teilworte und bei der Betrachtung der einzelnen Teilworte. Zerlegt man \(w\) z.B. in \(v \cdot 000 \cdot u\) und hat dies so gemacht, dass die \(000\) dort das erste Mal auftritt, dann weiß man, dass in \(v\) nicht die Zeichenkette \(000\) auftritt und sogar, dass \(v\) nicht auf \(0\) endet (sonst wäre das erste Mal, dass \(000\) auftritt, nämlich ein Symbol vorher gewesen).
Dies schließt unsere Betrachtungen zu Automaten und ihren akzeptierten Sprachen ab. Im nächsten Abschnitt geht es dann um zwei Konstruktionsmethoden, um einen Automaten zu einer Sprache \(M\) zu konstruieren.
Wir betonen zur Wiederholung das wichtige Vorgehen in diesem Abschnitt. Hat man für eine Sprache \(M\) einen DFA \(A\) konstruiert oder, was außer in der Lehre recht selten vorkommt, zu einem DFA \(A\) eine Idee, was die akzeptierte Sprache \(M\) ist, so ist \(L(A) = M\) zunächst nur eine Behauptung, die dann noch zu zeigen ist.
Hierzu zeigt man dann oft die zwei Teilmengenbeziehungen \(L(A) \subseteq M\) und \(M \subseteq L(A)\).
Mit \(L(A) \subseteq M\) zeigt man, dass jedes Wort, das der Automat akzeptiert, in \(M\) ist. Bei der Argumentation geht man von einem Wort \(w\) aus, das der Automat akzeptiert (\(w \in L(A)\)) und zeigt, dass dann auch \(w \in M\) gilt.
Mit \(M \subseteq L(A)\) zeigt man, dass jedes Wort aus \(M\) von dem Automaten akzeptiert wird. Man geht von einem (beliebigen!) Wort aus \(M\) aus ("Sei \(w \in M\), dann ...") und zeigt, dass dieses auch von \(A\) akzeptiert wird, also in \(L(A)\) ist.
Es sei noch mal betont, dass es nicht genügt nur eine der Teilmengenbeziehungen zu zeigen. \(L(A) \subseteq M\) zeigt nur, dass jedes Wort, das der Automat akzeptiert, auch in \(M\) ist. In \(M\) können aber noch Worte sein, die nicht in \(L(A)\) sind! Andersherum zeigt \(M \subseteq L(A)\) nur, dass jedes Wort in \(M\) vom Automaten akzeptiert wird, aber der Automat akzeptiert eventuell weitere Worte. Beides ist nicht wünschenswert. Entweder fehlen dem Automaten Fähigkeiten oder er kann zu wenig.
Man überlege sich zudem, dass es stets sehr leicht wäre, zu einer gegebenen Menge \(M\) einen Automaten zu bauen, der nur eine der Teilmengenbeziehungen erfüllt. Will man \(L(A) \subseteq M\) sicherstellen, so nimmt man einen Automaten der keine Endzustände hat. Für diesen gilt \(L(A) = \emptyset\) und damit sofort \(L(A) \subseteq M\). Will man \(M \subseteq L(A)\) sicherstellen, so nimmt man als Automat \(A\) einen Automat mit einem einzelnen Zustand \(z\), der sowohl Start- als auch Endzustand ist und für jedes Symbol \(x \in \Sigma\) eine Kante von \(z\) nach \(z\) besitzt. Dann gilt \(L(A) = \Sigma^*\) und damit sofort \(M \subseteq L(A)\). Nur eine der Teilmengenbeziehungen zu zeigen, genügt also nicht. Es muss \(L(A) = M\) gezeigt werden.
Zeitlimit: 0
Quiz-Zusammenfassung
0 von 4 Fragen beantwortet
Fragen:
1
2
3
4
Informationen
Hier ein paar Fragen zum Akzeptieren von Sprachen.
Sie haben das Quiz schon einmal absolviert. Daher können sie es nicht erneut starten.
Quiz wird geladen...
Sie müssen sich einloggen oder registrieren um das Quiz zu starten.
Sie müssen erst folgende Quiz beenden um dieses Quiz starten zu können:
Ergebnis
0 von 4 Frage korrekt beantwortet
Ihre Zeit:
Zeit ist abgelaufen
Sie haben 0 von 0 Punkten erreicht (0)
Kategorien
Nicht kategorisiert0%
1
2
3
4
Beantwortet
Vorgemerkt
Frage 1 von 4
1. Frage
Welche Sprache akzeptiert der folgenden DFA \(A\)?
Korrekt
Inkorrekt
Frage 2 von 4
2. Frage
Wie kann man \(L(A) = M\) beweisen?
Korrekt
Inkorrekt
Frage 3 von 4
3. Frage
Wie kann \(L(A) = M\) auch bewiesen werden?
Korrekt
Inkorrekt
Frage 4 von 4
4. Frage
Wie kann \(L(A) \subseteq M\) auch bewiesen werden?
Nach den Vorarbeiten des letzten Abschnittes sind wir nun in der Lage den deterministischen endlichen Automaten formal einzuführen. Wir erinnern noch einmal an die Überlegung, die wir in der Einleitung angestellt haben. Wichtig für den endlichen Automaten war, dass
wir ein System mit einer endlichen Anzahl von Zuständen haben,
von denen einer als Startzustand und
eine beliebige Teilmenge als Endzustände hervorgehoben sind,
dass Zustandsübergänge möglich sind und
dass das System sich stets in genau einem Zustand befindet.
Formal können wir dies wie folgt exakt beschreiben.
Ein deterministischer, endlicher Automat (DFA) ist ein \(5\)-Tupel
$$ A = (Z, \Sigma, \delta, z_0, Z_{end}) $$
mit:
Der endlichen Menge von Zuständen \(Z\).
Dem endlichen Alphabet \(\Sigma\) von Eingabesymbolen.
Der Überführungsfunktion \(\delta: Z \times \Sigma \rightarrow Z\).
Dem Startzustand \(z_0 \in Z\).
Der Menge der Endzustände \(Z_{end} \subseteq Z\).
Als graphische Darstellung wählen wir Kreise für die Zustände und notieren die Bezeichnung des Zustandes meist im Kreis. Der Startzustand wird mit einer eingehenden Kante ohne Ursprung notiert, Endzustände mit Doppelkreisen. Die Überführungsfunktion wird mit beschrifteten, gerichteten Kanten notiert. Ist bspw. \(\delta(z,a) = z‘\), so gibt es eine gerichtete Kante von \(z\) nach \(z‘\), die mit \(a\) beschriftet ist. Ein Beispiel ist der abgebildete Automat:
Mit den Zustandsmenge \(Z = \{z_0, z_1\}\), dem Startzustand \(z_0\), der Endzustandsmenge \(Z_{end} = \{z_1\}\) und der Überführungsfunktion \(\delta\), die durch \(\delta(z_0, 0) = z_0\), \(\delta(z_0, 1) = z_1\) und \(\delta(z_1, 0) = z_1\) gegeben ist. (Man beachte, dass \(\delta(z_1, 1)\) nicht definiert ist. Die Funktion \(\delta\) muss nicht total sein und wir werden gleich sagen, dass der Automat in solchen Fällen blockiert.) Sofern nicht anders erwähnt ist das Eingabealphabet \(\Sigma\) die Menge der Symbole, die als Kantenbeschriftungen benutzt werden. Im abgebildeten Beispiel wäre also \(\Sigma = \{0,1\}\). Eine solche graphische Darstellung eines DFA \(A\) wird als Zustandsübergangsdiagramm von \(A\) bezeichnet.
Dies beschreibt nun zunächst nur die Struktur eines DFA. Um auch seine Dynamik, d.h. sein Verhalten beschreiben zu können. Machen wir uns zunächst noch einmal informal klar, wie ein DFA arbeiten soll. Die Eingabe für einen DFA \(A = (Z, \Sigma, \delta, z_0, Z_{end})\) ist ein Wort aus \(\Sigma^*\). Sei dieses Wort mit \(w\) bezeichnet (also \(w \in \Sigma^*\) ist \(\Sigma = \{a,b\}\), so könnte \(w\) z.B. \(abbb\) sein). \(A\) arbeitet dann wie folgt:
\(A\) beginnt im Startzustand \(z_0\).
Beginnt \(w\) mit dem Symbol \(x \in \Sigma\),
so wird der Nachfolgezustand nun durch \(\delta(z_0, x)\) bestimmt.
Dies wird dann in dem nun aktuellen Zustand und mit dem Restwort fortgeführt (ist \(A\) also z.B. nun in \(z\) und ist der nächste Buchstabe ein \(y\), so ist der Nachfolgezustand \(\delta(z,y)\) usw.)
Das Wort \(w\) wird akzeptiert, wenn
\(w\) bis zum Ende gelesen werden kann und
der Automat dann in einem Endzustand ist.
Das Wort wird nicht akzeptiert, wenn der Automat entweder nach Lesen des Wortes nicht in einem Endzustand ist oder wenn das Wort nicht zu Ende gelesen werden kann. Letzteres passiert, wenn er in einem Zustand \(z\) ist und das Symbol \(x\) als nächstes gelesen werden soll, es aber keinen Nachfolgezustand gibt, d.h. wenn \(\delta(z,x)\) nicht definiert ist (oder im Diagramm: wenn es keine Kante aus \(z\) heraus gibt, die mit \(x\) beschriftet ist).
Betrachten wir das Beispiel aus Abbildung 2.4. Der Startzustand ist \(z_0\) (markiert durch den eingehenden Pfeil), der einzige Endzustand ist \(z_2\) (markiert durch die doppelten Kreise). Die Werte von \(\delta\) werden durch die Kantenrichtungen und Kantenbeschriftungen ausgedrückt, bspw. ist \(\delta(z_0, a) = z_1\) und \(\delta(z_0, b)\) nicht definiert (beginnt ein Wort also mit \(b\) kann der Automat dieses Wort nicht akzeptieren, da er es nicht zu Ende lesen kann).
2.4: DFA mit Eingabewort \(abba\).
Im Beispiel der Abbildung mit dem Wort \(abba\) wird nun zuerst das \(a\) gelesen und dabei der Zustandswechsel nach \(z_1\) gemacht (Abbildung 2.5). Dort können dann mittels der \(b\)-Schleife die beiden \(b\) gelesen werden und im Anschluss wird mit der \(a\)-Kante von \(z_1\) nach \(z_2\) in den Zustand \(z_2\) gewechselt (Abbildung 2.6).
Da \(z_2\) nun ein Endzustand ist und das Wort zu Ende gelesen wurde, wird \(abba\) akzeptiert. In Fällen, in denen der Automat bei einem Wort nicht diese beiden Bedingungen erfüllt, wird das Wort nicht akzeptiert.
Um es zu betonen: Ein Wort \(w\) wird von einem DFA \(A\) akzeptiert, wenn der Automat das Wort bis zum Ende lesen kann (also nie der Fall auftritt, dass \(A\) in einem Zustand \(z\) ist, den nächsten Buchstaben \(x\) des Wortes aber nicht lesen kann, da \(\delta(z,x)\) nicht definiert ist) und dann in einem Endzustand ist.
Im Beispiel wird das Wort \(abba\) akzeptiert, da beide Bedingungen zutreffen.
Das Wort \(abb\) wird bspw. nicht akzeptiert, da das Wort zwar zu Ende gelesen werden kann, der Automat dann aber immer noch in \(z_1\) ist und \(z_1\) kein Endzustand ist. Das Wort \(ba\) wird nicht akzeptiert, da der Automat in \(z_0\) das \(b\) nicht lesen kann (der Übergang \(\delta(z_0,b)\) ist nicht definiert). Das Wort \(aab\) wird nicht akzeptiert, da der Automat nach \(aa\) zwar in dem Endzustand \(z_2\) ist, das Wort dann aber noch nicht zu Ende gelesen ist (und auch nicht mehr zu Ende gelesen werden kann, da \(\delta(z_2, b)\) nicht definiert ist).
Zuletzt sei betont, dass beide Bedingungen gleichzeitig eintreten müssen: das Wort muss zu Ende gelesen sein und der Automat muss dann in einem Endzustand sein. Ist im Beispiel \(z_1\) ein Endzustand und \(z_2\) kein Endzustand, so würde bspw. \(aa\) nicht akzeptiert werden. Nach Lesen von \(a\) ist der Automat zwar in \(z_1\), was ja jetzt ein Endzustand ist, hat das Eingabewort \(aa\) aber noch nicht zu Ende gelesen. Mit dem zweiten \(a\) verlässt der Automat den Zustand \(z_1\) dann wieder und wechselt nach \(z_2\), was nun ja aber kein Endzustand ist. Das Wort \(aa\) ist dann zwar zu Ende gelesen, aber der Automat ist nun in \(z_2\) und akzeptiert nicht. Wichtig ist also nicht, dass irgendwann einmal ein Endzustand besucht wurde, sondern dass der Automat das Wort zu Ende gelesen hat und dann in einem Endzustand ist.
Bevor wir die von einem Automaten akzeptierten Wörter und damit die akzeptierte Sprache formal einführen, erweitern wir zunächst noch die Überführungsfunktion \(\delta\) und führen den Begriff der Konfiguration und der Erfolgsrechnung ein. Die letzteren beiden Begriffen werden meist erst für komplexere Automatenmodelle eingeführt, aber es ist eine gute Übung sie bereits hier einzuführen.
Sei \(A = (Z, \Sigma, \delta, z_0, Z_{end})\) ein DFA. Die erweiterte Überführungsfunktion \(\hat{\delta}: Z \times \Sigma^* \rightarrow Z\) wird für alle \(z \in Z\), \(x \in \Sigma\) und \(w \in \Sigma^*\) rekursiv definiert durch
Sei \(A\) durch folgendes Zustandsübergangsdiagramm gegeben.
Dann ist \(\hat{\delta}(z_0, 001) = \hat{\delta}(z_0, 01) = \hat{\delta}(z_0, 1) = z_1\) und abkürzend schreibt man dann einfach \(\hat{\delta}(z_0, 001) = z_1\) oder bricht an einer beliebigen für einen interessanten Stelle ab.
Definition 2.1.4 (Konfiguration und Rechnung)
Eine Konfiguration eines DFA \(A\) ist ein Tupel \((z,w) \in Z \times \Sigma^*\) mit der Bedeutung, dass \(A\) im Zustand \(z\) ist und noch das Wort \(w\) zu lesen ist.
Ein Konfigurationsübergang ist dann $$(z,w) \vdash (z‘,v)$$ genau dann, wenn \(w = xv\), \(x \in \Sigma\) und \(\delta(z,x) = z‘\) ist.
Eine Rechnung auf dem Wort \(w \in \Sigma^*\) ist eine Folge von Konfigurationsübergängen, die in \((z_0, w)\) beginnt.
Endet die Rechnung in \((z‘, \lambda)\) und ist \(z‘ \in Z_{end}\), so ist dies eine Erfolgsrechnung und \(w\) wird akzeptiert.
Sei wieder \(A\) durch folgendes Zustandsübergangsdiagramm gegeben. Dann ist bei Eingabe \(001\) die Konfiguration zu Beginn \((z_0, 001)\). Auf diesem Wort hat der Automat die Rechnung
$$(z_0, 001) \vdash (z_0, 01) \vdash (z_0, 1) \vdash (z_1, \lambda)$$
Da die Rechnung in \((z_1, \lambda)\) endet und \(z_1\) ein Endzustand ist, ist dies sogar eine Erfolgsrechnung.
Damit können wir nun formal den wichtigen Begriff der akzeptierten Sprache eines DFA definieren und damit die Sprachfamilie der regulären Sprachen.
Definition 2.1.5 (Akzeptierte Sprache)
Die von einem DFA \(A\) akzeptierte Sprache ist die Menge
Eine von einem DFA akzeptierte Sprache wird auch als reguläre Menge bezeichnet und die Familie aller regulären Mengen wird mit \(REG\) bezeichnet.
Man beachte, wie unsere obige intuitive Beschreibung von der Definition erfasst wird. In \(L(A)\) sind genau jene Worte, die von \(A\) zu Ende gelesen werden können und die \(A\) dabei vom Startzustand \(z_0\) in einen Endzustand überführen.
Sei noch einmal betont, dass in \(L(A)\) genau die Worte sind, die von \(A\) akzeptiert werden, nicht mehr und nicht weniger. Wenn wir später also behaupten, dass in einer Menge \(M\) gerade die Worte sind, die von einem Automaten \(A\) akzeptiert werden, dann behaupten wir also \(L(A) = M\) (und müssen dies dann noch beweisen). Wir kommen darauf gleich noch zu sprechen, aber man mache sich noch einmal jetzt schon klar, dass in \(L(A)\) exakt die Worte enthalten sind, die \(A\) akzeptiert, nicht weniger, nicht mehr. Soll man also z.B. einen Automaten konstruieren, der alle Worte akzeptiert, die mit \(a\) beginnen, so muss man darauf achten, dass man alle Worte mit dieser Eigenschaft akzeptiert und nicht weniger - aber eben auch nicht mehr.
Zuletzt noch zwei Begriffe, die im Zusammenhang mit endlichen Automaten sowohl bei der Konstruktion als auch bei Beweisen öfter auftreten.
Definition 2.1.6
Ein DFA \(A = (Z, \Sigma, \delta, z_0, Z_{end})\) heißt
vollständig, wenn zu jedem \((z,x) \in Z \times \Sigma\) ein \(z‘\) existiert mit \(\delta(z,x) = z‘\).
initial zusammenhängend, wenn es zu jedem \(z \in Z\) ein Wort \(w\) gibt mit \(\hat{\delta}(z_0,w) = z\).
Ist ein Automat vollständig, so gibt es also zu jedem Symbol des Eingabealphabets eine Kante in jedem Zustand. Dies führt dazu, dass jede Eingabe (zu Ende) gelesen werden kann. Initial zusammenhängend bedeutet, dass jeder Zustand erreichbar ist. Dies ist bisweilen gut zu wissen, da die anderen Zustände im Grunde nutzlos sind. Man spricht auch von einer initialen Zusammenhangskomponente, wenn man die Zustände meint, die vom Startzustand aus erreichbar sind und schränkt einen DFA oft auf diese ein.
Wichtige Begriffe bis hierhin waren zu den formalen Sprachen die Begriffe Alphabet, Konkatenation, Wort, leeres Wort und die Notationen \(R^+\), \(R^*\), \(\Sigma^+\), \(\Sigma^*\), \(R^0\), \(R^1\), \(R^i\), \(w^0\), \(w^1\), \(w^i\), sowie zu den endlichen Automaten die Begriffe DFA, Zustände, Startzustand, Endzustände, Überführungsfunktion, erweitere Überführungsfunktion, vollständig, initial zusammenhängend, Konfiguration, Konfigurationsübergang, Rechnung, Erfolgsrechnung, akzeptierte Sprache, reguläre Menge und die Sprachfamilie REG. Alle diese Begriffe sind wichtig und sollten bekannt sein, da wir auf ihrer Grundlage aufbauen und einem sonst im weiteren Verlauf wichtige Vokabeln fehlen. Daher diese Begriffe ruhig noch einmal angucken.
Zeitlimit: 0
Quiz-Zusammenfassung
0 von 4 Fragen beantwortet
Fragen:
1
2
3
4
Informationen
Hier ein paar Fragen zu DFAs.
Sie haben das Quiz schon einmal absolviert. Daher können sie es nicht erneut starten.
Quiz wird geladen...
Sie müssen sich einloggen oder registrieren um das Quiz zu starten.
Sie müssen erst folgende Quiz beenden um dieses Quiz starten zu können:
Ergebnis
0 von 4 Frage korrekt beantwortet
Ihre Zeit:
Zeit ist abgelaufen
Sie haben 0 von 0 Punkten erreicht (0)
Kategorien
Nicht kategorisiert0%
1
2
3
4
Beantwortet
Vorgemerkt
Frage 1 von 4
1. Frage
Wie viele Startzustände kann ein endlicher Automat haben?
Korrekt
Inkorrekt
Frage 2 von 4
2. Frage
Wie viele Endzustände kann ein endlicher Automat haben?
Korrekt
Inkorrekt
Frage 3 von 4
3. Frage
Wann akzeptiert ein endlicher Automat ein Eingabewort?
Korrekt
Inkorrekt
Frage 4 von 4
4. Frage
Sei \(Z = \{z_0, z_1\}\), \(z_0\) der Startzustand, \(z_1\) der einzige Endzustand. Ferner sei \(\delta(z_0, 0) = z_0\), \(\delta(z_0,1) = z_1\) und \(\delta(z_1, 0) = z_1\). Skizzieren Sie das Zustandsübergangsdiagramm dieses DFA \(A\). Welche Sprache akzeptiert er?
Um die bisherige informale Beschreibung mathematisch zu präzisieren brauchen wir einige Begriffe und Notationen. Das sind neben den schon bekannten Begriffen wie Mengen, Funktionen und Relationen, die neuen Begriffe für formale Sprachen. Diese werden nachfolgend eingeführt. Im Anschluss wird der deterministische endliche Automat eingeführt.
Eine formale Sprache ist eine Menge von Worten. Wir werden also den Begriff eines Wortes brauchen, wofür wir wiederum den Begriff eines Zeichens (als Baustein eines Wortes) brauchen, sowie den Begriff der Konkatenation, so dass einzelne Zeichen hintereinander geschrieben werden können.
Im einzelnen ist ein Alphabet eine (total geordnete) endliche Menge von unterschiedlichen Zeichen (alternativ: Buchstaben oder Symbole). Wir notieren diese Menge meistens mit \(\Sigma\). Es ist dann z.B. \(\Sigma = \{a, b, c\}\) für das Alphabet mit den Zeichen \(a\), \(b\) und \(c\).
Die Konkatenation wird mit \(\cdot\) notiert und ist die Operation zum Hintereinanderschreiben von Buchstaben. So ergeben sich Worte, auf die die Operation dann erweitert wird. Z.B. ist \(a \cdot b = ab\) und dann \(ab \cdot c = abc\). Diese Konkatenation wird auf Mengen von Wörtern erweitert, so dass wir z.B.
$$\{ab, aba\} \cdot \{ab, b\} = \{ab \cdot ab, ab \cdot b, aba \cdot ab, aba \cdot b \}$$
erhalten (was das gleiche ist wie \(\{abab, abb, abaab\}\), da der \(\cdot\) oft weggelassen wird.
Das leere Wort (das Wort mit \(0\) Buchstaben) wird mit \(\lambda\) oder \(\epsilon\) bezeichnet. Es ist nie in einem Alphabet enthalten, sondern ist das spezielle Wort das aus \(0\) Symbolen eines Alphabets besteht.
Mit \(|w|\) wird die Länge eines Wortes \(w\) notiert. Z.B. ist \(|001| = 3\), \(|00111| = 5\) und \(|\lambda| = 0\). Mit \(|w|_x\) ist die Anzahl der \(x\) in \(w\) gemeint, wobei \(x\) ein Symbol ist, z.B. ist \(|2202|_2 = 3\).
Als weitere Notation schreiben wir \(w^1 = w, w^2 = w \cdot w\) und \(w^k = w^{k-1} \cdot w\) (\(k \geq 2\)) und als Spezialfall \(w^0 = \lambda\). Die hochgestellte Zahl \(i\) bei \(w^i\) gibt also an, wie oft wir ein Wort hintereinander schreiben wollen. Ähnlich wie oben erweitern wir diese Operation auf Mengen, so dass wir für eine Menge von Worten \(R\) dann \(R^1 = R\), \(R^2 = R \cdot R\) und allgemein \(R^n = R^{n-1} \cdot R\) haben (Spezialfall: \(R^0 = \{\lambda\}\)). In \(R^i\) sind also alle Wörter enthalten, die man erhält, wenn man \(i\) Wörter aus \(R\) auswählt und diese hintereinander schreibt.
Zuletzt zwei besonders wichtige Definitionen, die auf obigem aufbauen. Wir setzen
\(R^+ := \cup_{i \geq 1} R^i \text{ mit } R^1 := R \text{ und } R^{i+1} = R^i \cdot R\)
\(R^* := R^+ \cup \{\lambda\}\)
In \(R^+\) sind also jene Wörter, die man erhält, wenn man beliebig oft (aber endlich oft!) Wörter aus \(R\) hintereinander schreibt und in \(R^*\) ist zusätzlich auf jeden Fall noch \(\lambda\) enthalten (\(\lambda\) kann auch in \(R^+\) enthalten sein, aber nur wenn \(\lambda \in R\) gilt).
Besonders wichtig ist für uns der Spezialfall \(\Sigma^*\) für ein Alphabet \(\Sigma\). Dabei ist \(\Sigma^*\) dann die Menge aller endlichen Wörter (über dem Alphabet \(\Sigma\)). Jede (Teil-)Menge \(L \subseteq \Sigma^*\) heißt formale Sprache.
Wir fassen die vielen Definitionen noch einmal zusammen.
Definition 2.1.1 (Zeichen, Worte, Sprache)
Ein Alphabet ist eine (total geordnete) endliche Menge von unterschiedlichen Zeichen (alternativ: Buchstaben oder Symbole).
Die Konkatenation \(\cdot\) ist die Operation zum Hintereinanderschreiben von Buchstaben. So ergeben sich Worte auf die die Operation dann erweitert wird. (Z.B. ist \(a \cdot b = ab\) und dann \(ab \cdot c = abc\).) Die Konkatenation wird auf Mengen von Wörtern erweitert, wobei dann \(R \cdot S = \{u \cdot v \mid u \in R, v \in S\}\) gilt.
Das leere Wort (Wort mit \(0\) Buchstaben) wird mit \(\lambda\) oder \(\epsilon\) bezeichnet (das leere Wort ist nie in einem Alphabet enthalten!).
Sei \(\Sigma\) ein Alphabet, \(x \in \Sigma\) ein Symbol und \(w\) ein Wort bestehend aus Symbolen aus \(\Sigma\). Mit \(|w|\) wird die Länge von \(w\) notiert, also z.B. \(|001| = 3\) und \(|00111| = 5\). Außerdem ist \(|\lambda| = 0\). Ferner wird mit \(|w|_x\) die Anzahl der \(x\) in \(w\) notiert. Z.B. ist mit \(\Sigma = \{0,1,2\}\) dann \(|2202|_2 = 3\), \(|2202|_1 = 0\) und \(|2202|_0 = 1\).
Wir schreiben \(w^1 = w, w^2 = w \cdot w\) und \(w^k = w^{k-1} \cdot w\) (\(k \geq 2\)) und als Spezialfall \(w^0 = \lambda\). Für eine Menge von Worten \(R\) schreiben wir ebenso \(R^1 = R\), \(R^2 = R \cdot R\) und \(R^k = R^{k-1} \cdot R\) und als Spezialfall \(R^0 = \{\lambda\}\).
Ferner setzen wir
\(R^+ := \cup_{i \geq 1} R^i \text{ mit } R^1 := R \text{ und } R^{i+1} = R^i \cdot R\)
\(R^* := R^+ \cup \{\lambda\}\)
Sei \(\Sigma\) ein Alphabet, dann bezeichnen wir mit \(\Sigma^*\) die Menge aller endlichen Wörter (über dem Alphabet \(\Sigma\)).
In diesem Kapitel wollen wir den endlichen Automaten einführen, das einfachste Automatenmodell, das aber recht nützlich ist und als Grundlage für weitere Automatenmodell dient.
Um uns diesem zu nähern, betrachten wir zunächst einen einfachen Lichtschalter. Dieser kann 'an' oder 'aus' sein, also in genau einem von zwei Zuständen. Zudem sind durch die Aktion 'Schalter betätigen' Zustandsübergänge möglich. Abbildung 2.1 zeigt eine graphische Darstellung. Die Kantenbeschriftung \(b\) steht dabei für die Betätigung des Schalters.
Gehen wir nun davon aus, dass der Lichtschalter zu Beginn ausgeschaltet ist, so soll der Zustand 'aus' zudem der (eindeutige) Startzustand sein. Wollen wir ferner bspw. ein System modellieren, in dem nur jene Aktionsfolgen „gut“ sind, bei denen das Licht am Ende wieder ausgeschaltet ist, so modellieren wir den Zustand 'aus' noch als Endzustand. Abbildung 2.2 zeigt das ergänzte System. Der Pfeil in den Zustand 'aus' hinein deutet an, dass 'aus' der Startzustand ist. Der doppelte Kreis um 'aus' bedeutet, dass 'aus' ein Endzustand ist.
Damit haben wir bereits alle Komponenten eines endlichen Automaten vorliegen.
Wichtig ist bei diesem Beispiel, dass
wir ein System mit einer endlichen Anzahl von Zuständen haben,
von denen einer als Startzustand und
eine beliebige Teilmenge als Endzustände hervorgehoben sind,
dass Zustandsübergänge möglich sind und
dass das System sich stets in genau einem Zustand befindet.
Abbildung 2.1: Modell eines einfachen Lichtschalters.
Abbildung 2.2: Verbessertes Modell eines einfachen Lichtschalters.
Das dynamische Verhalten des Systems lässt sich wie folgt beschreiben: Wir beginnen im Startzustand (hier 'aus'). Dann können genau die Aktionen ausgeführt werden, die mit Kanten aus diesem Zustand herausgehen. In diesem Fall gibt es nur die Aktion \(b\), die uns in den Zustand 'an' überführt. Von dort geht es dann weiter. Führen wir die Aktion \(b\) bspw. dreimal hintereinander aus (wir schreiben dafür später \(b \cdot b \cdot b\) oder auch einfach \(bbb\)), so enden wir im Zustand 'an'. Führen wir \(b\) hingegen nur zweimal aus (also \(b \cdot b\)), so enden wir im Zustand 'aus'. Da 'aus' ein Endzustand ist, sagen wir, dass \(b \cdot b\) akzeptiert wird (\(bbb\) hingegen nicht, da 'an' kein Endzustand ist).
Aus der bisherigen Beschreibung ist der Nutzen von endlichen Automaten und der Bezug zur Informatik vielleicht noch nicht ersichtlich. Tatsächlich sind mit endlichen Automaten zunächst eine Vielzahl von Anwendungen und Problemen modellierbar. Beispielsweise werden endliche Automaten benutzt, um Schaltkreise oder Kommunikationsprotokolle zu modellieren. Die Modelle dienen dabei insbesondere zur Kommunikation in Entwicklungsteams und zur Fehlerfindung. Daneben sind endliche Automaten wichtig, um auf ihnen aufbauende kompliziertere Automatenmodelle zu verstehen. Beispielsweise wollen wir später die Turingmaschine einführen, mit der man dann formal argumentieren kann, welche Probleme nicht von einem Computer gelöst werden können.
Während die bisher skizzierte Idee eines Systems mit Aktionen recht intuitiv ist (man denke z.B. an einen Fahrkarten- oder einen Süßigkeitenautomaten, die stets in einem Zustand sind und durch Aktionen in andere Zustände überführt werden), wird in der (theoretischen) Informatik meist eine andere Modellvorstellung verwendet. Die beiden Vorstellungen können aber ineinander überführt werden und sind daher im Grunde identisch. Die in der Informatik gängige Vorstellung ist die eines Automaten, der ein Eingabewort auf einem Eingabeband hat und dieses Wort Buchstabe für Buchstabe liest. Abbildung 2.3 zeigt eine skizzenhafte Darstellung. Dieser Automat besitzt drei Zustände,\(z_0\),\(z_1\),\(z_2\), wobei\(z_0\) der Startzustand und\(z_2\) ein Endzustand ist. An den Kantenbeschriftungen kann man zudem erkennen, dass er\(a\)s und\(b\)s lesen kann.
Abbildung 2.3: Skizze eines endlichen Automaten.
Das Eingabeband ist über dem Automaten notiert. Das Eingabewort ist \(abba\) (die weiteren leeren Kästchen und die schwarzen Punkte sollen andeuten, dass man auch längere Worte auf diesem Band notieren kann) und der gestrichelte Pfeil zwischen Automat und Eingabeband zeigt an, welcher Buchstabe des Wortes gerade gelesen wird (man spricht hier auch vom Lesekopf). Ist der Automat zu Anfang in \(z_0\), so kann er nun das \(a\) lesen (da es eine \(a\)-Kante aus \(z_0\) heraus gibt). Der Automat wechselt dann in den Zustand \(z_1\) und der Lesekopf wandert ein Feld weiter. Nun können die zwei \(b\) gelesen werden, wobei der Automat im Zustand \(z_1\) bleibt. Der letzte Buchstabe (das \(a\)) kann dann auch gelesen werden, wobei der Automat in den Zustand \(z_2\) wechselt. Da dies ein Endzustand ist und das Wort bis zum Ende gelesen wurde, akzeptiert der Automat das Wort \(abba\).
Die Vorstellung eines Eingabebandes ist historisch gewachsen und erscheint heute eher altertümlich. Sie ist aber eine gute Abstraktion und man kann sich recht gut überlegen, dass die Vorstellungen eines Wortes im (Haupt-)Speicher oder einer Folge von Aktionen wie zu Anfang recht ähnlich sind. Das wichtige ist hier der Automat, der ein Wort von links nach rechts liest und dieses letztendlich akzeptiert oder nicht. Nicht akzeptiert wird dabei ein Wort dann, wenn entweder das Wort gar nicht zu Ende gelesen werden kann (dies tritt auf, wenn der Automat in einem Zustand \(z\) ist und einen Buchstaben \(x\) lesen soll, zu dem es keine Kante aus \(z\) heraus gibt; man sagt dann, der Automat blockiert) oder aber das Wort zu Ende gelesen werden kann, der Automat dann aber nicht in einem Endzustand ist.
Die Menge aller Wörter, die ein gegebener Automat akzeptiert, bezeichnen wir als seine akzeptierte Sprache. Warum diese wichtig ist, werden wir in der Vorlesung genauer behandeln. Im obigen Beispiel aus Abbildung 2.2 akzeptieren wir z.B. genau die Wörter, die nur aus \(b\)s bestehen und die eine gerade Anzahl \(b\)s enthalten. Im Beispiel aus Abbidlung 2.3 werden jene Wörter aus \(a\)s und \(b\)s akzeptiert, die mit genau einem \(a\) beginnen und enden und die dazwischen beliebig viele (auch \(0\)) \(b\)s haben.
Man kann sich die Frage stellen, ob solche Automaten einen Anwendungsfall haben, da sie recht einfach erscheinen. Erstens sind solche endlichen Automaten die Grundlage für prinzipiell alle weiteren Automatenmodelle, mit denen dann sehr viel komplexere Systeme modelliert werden können. Zweitens sind bereits endliche Automaten für viele Anwendungen von Bedeutung. Bspw. basiert die Worterkennung bei einem Compiler (um bspw. das Schlüsselwort 'if' zu finden) auf endlichen Automaten. Auch Protokolle und viele Anwendungen aus der technischen Informatik lassen sich mit endlichen Automaten (oder leichten Varianten davon) modellieren und dann implementieren (nachdem sich das Modell als hoffentlich fehlerfrei erwiesen hat).